TL;DR
- 단어 빈도를 기반으로, 모든 문서에 흔히 나오는 단어에는 페널티를 주어 중요한 단어를 점수화한다.
- 값이 클수록 그 문서에서 중요한 단어다.
- 단어와 문서가 많아질수록 결과 행렬은 sparse matrix가 된다.
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)는 문서 안에서 한 단어가 얼마나 중요한지를 점수화하는 가중 방식이다. 특정 문서에 자주 등장할수록(TF) 점수를 높이고, 모든 문서에 흔히 등장할수록(IDF) 점수를 낮춘다.
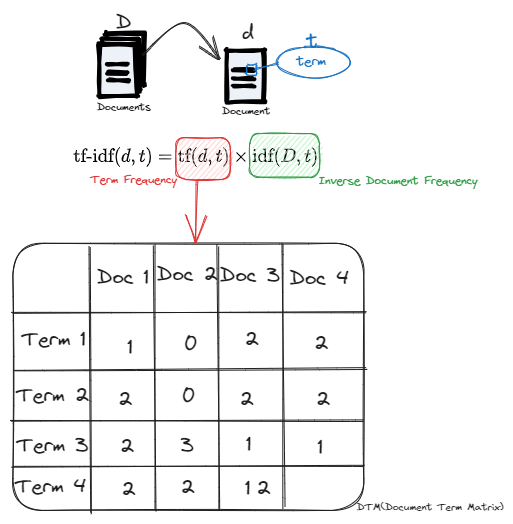
Term Frequency (TF)
Term Frequency는 한 문서 안에서 특정 단어가 얼마나 자주 등장하는지를 나타낸다. 보통 raw count를 그대로 쓰기보다, 문서 길이 차이를 보정하기 위해 문서 안 전체 단어 수로 나눈 상대 빈도로 정의한다.
여기서 는 문서 안에서 단어 가 등장한 횟수다. 여러 문서의 TF를 모으면 행이 문서, 열이 단어인 DTM(Document Term Matrix) 형태로 표현된다.
Document Frequency (DF)
Document Frequency는 특정 단어 가 등장한 문서의 수 다. 핵심은 단어가 몇 번 등장했는지가 아니라 몇 개의 문서에 등장했는지다. 예를 들어 “사과”가 세 문서에 나타났다면, 그 세 문서 안에서 총 100번 등장하더라도 이다. DF가 크다는 것은 그 단어가 다수의 문서에 두루 쓰인다는 뜻이고, 따라서 특정 문서를 구별하는 힘이 약하다는 신호다.
Inverse Document Frequency (IDF)
Inverse Document Frequency는 DF가 큰 단어, 즉 여러 문서에 흔히 나오는 단어의 가중치를 낮추는 값이다. 단순히 DF의 역수를 쓰기보다, 전체 문서 수 을 DF로 나눈 뒤 로그를 취해 정의하는 것이 일반적이다.
DF가 클수록 IDF는 작아지므로, 조사나 불용어처럼 거의 모든 문서에 나오는 단어는 낮은 가중치를 받는다. 로그를 취하는 이유는 DF가 아주 큰 단어의 영향을 완만하게 누르기 위해서다.
TF-IDF
TF-IDF는 이 두 값을 곱해 단어의 중요도를 매긴다.
특정 문서에 자주 등장하면 TF가 커져 점수가 올라가고, 그 단어가 모든 문서에 흔하면 IDF가 작아져 점수가 깎인다. 그 결과 “이 문서에서만 두드러지는 단어”가 높은 점수를 받는다. 값이 클수록 해당 문서를 잘 대표하는 단어이고, 작을수록 변별력이 낮은 단어다.
구현
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"안녕하세요 이것은 tf-idf 테스트입니다.",
"정말 제대로 이해하고 있을까요?",
"예제를 통해 알아 봅시다."
]
# 1. init TfidfVectorizer and fit
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus) # X is a DTM(Document Term Matrix) that contains a tf-idf score element
feature_names = vectorizer.get_feature_names_out() # feature_names is a list of terms(words)
#2. Extract the top-k most important words(those with the highest TF-IDF socres) from each document
for i, doc in enumerate(corpus):
print(f"\nTop words in document {i + 1}:")
# Extract TF-IDF scores for the respective document
tfidf_scores = X[i].toarray().flatten()
# Sort TF-IDF scores in descending order and output the top-k words
# So, sort in ascending order, take the top 3, and reverse for the top 3 words
top_indices = tfidf_scores.argsort()[-3:][::-1]
for idx in top_indices:
print(f"{feature_names[idx]}: {tfidf_scores[idx]}")
Discussion
Comments
댓글은 승인 후 공개됩니다.