TL;DR
- BERTScore는 PLM의 Contextual Embedding을 활용하여 토큰 레벨의 의미적 유사성을 평가하는 지표다.
- Greedy Matching과 IDF 가중치를 결합하여 어휘 일치를 넘어선 문맥적 유사도를 산출한다.
BERTScore (Evaluating Text Generation with BERT)
기존의 n-gram 기반 메트릭(BLEU 등)은 어휘가 정확히 일치하지 않으면 유사도를 낮게 평가하는 한계가 있다. BERTScore는 PLM의 임베딩 공간에서 코사인 유사도를 계산함으로써, 유의어나 문맥적 의미가 유사한 문장 쌍을 더 정확하게 평가한다.
1. 방법론 (Methods)
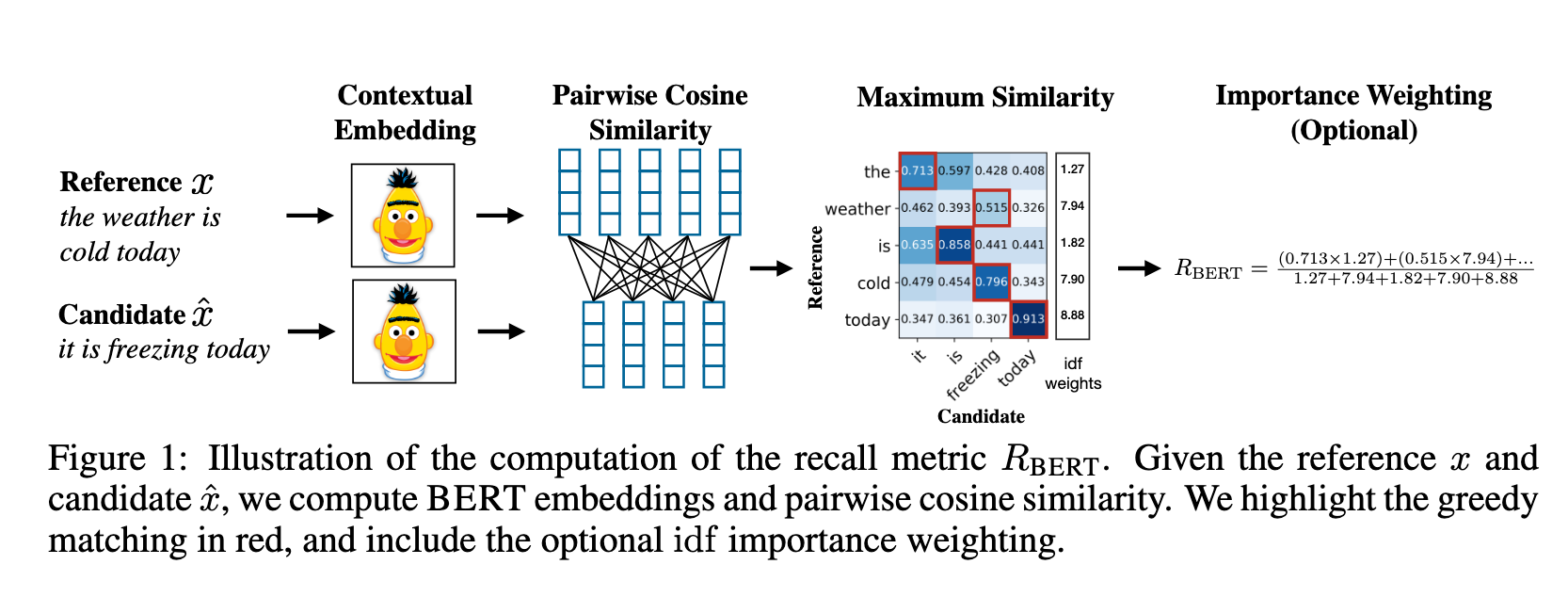
프로세스
- Contextual Embedding: Candidate(Hypothesis)와 Reference 문장을 BERT에 입력하여 각 토큰의 임베딩 벡터를 추출한다.
- Similarity Matrix: 두 문장의 토큰 쌍 간의 모든 코사인 유사도를 계산하여 유사도 행렬을 생성한다.
- Greedy Matching:
- Recall (): 참조 문장의 각 토큰이 후보 문장의 어떤 토큰과 가장 유사한지 확인 (Row-wise max pooling).
- Precision (): 후보 문장의 각 토큰이 참조 문장의 어떤 토큰과 가장 유사한지 확인 (Column-wise max pooling).
- Importance Weighting: (선택 사항) IDF를 가중치로 활용하여 토큰별 중요도를 반영한다.
상세 계산 예시
- Reference (A): [“cat”, “on”, “mat”]
- Candidate (B): [“cat”, “sits”, “on”, “rug”]
| Token (A) | cat (B) | sits (B) | on (B) | rug (B) |
|---|---|---|---|---|
| cat (A) | 0.95 | 0.20 | 0.10 | 0.05 |
| on (A) | 0.10 | 0.30 | 0.90 | 0.10 |
| mat (A) | 0.05 | 0.40 | 0.20 | 0.80 |
- Recall (): 참조 문장(A)의 각 행에서 최대값을 선택하여 평균 산출.
- Precision (): 후보 문장(B)의 각 열에서 최대값을 선택하여 평균 산출.
- F1 Score:
2. 코드 레벨 분석 (greedy_cos_idf)
핵심 스코어링 로직
def greedy_cos_idf(ref_embedding, hyp_embedding, ref_idf, hyp_idf):
# (1) L2 정규화 -> 내적 = 코사인 유사도
ref_embedding.div_(torch.norm(ref_embedding, dim=-1).unsqueeze(-1))
hyp_embedding.div_(torch.norm(hyp_embedding, dim=-1).unsqueeze(-1))
# (2) 유사도 행렬 생성: [batch, hyp_len, ref_len]
sim = torch.bmm(hyp_embedding, ref_embedding.transpose(1, 2))
# (3) Greedy matching
word_precision = sim.max(dim=2)[0] # hyp 각 토큰 -> ref 내 최적 매칭 (Precision)
word_recall = sim.max(dim=1)[0] # ref 각 토큰 -> hyp 내 최적 매칭 (Recall)
# (4) IDF 가중 평균
P = (word_precision * hyp_idf).sum(dim=1)
R = (word_recall * ref_idf).sum(dim=1)
return P, R, 2 * P * R / (P + R)Dimension 방향 이해
- 코드의
sim행렬([H, R])은 위 예시 행렬([R, H])의 전치 형태다.sim.max(dim=2): 가로 방향(Reference 축) 최대값 Precisionsim.max(dim=1): 세로 방향(Candidate 축) 최대값 Recall
3. 주요 기술적 개념 (Key Concepts)
레이어 선택 (Layer Selection)
- BERT의 모든 레이어가 동일하게 유용하지 않다. 논문 실험 결과 중간 레이어가 의미적 유사성을 가장 잘 포착하며, 최종 레이어는 사전 학습 목적 함수(MLM)에 특화되어 성능이 떨어진다.
- 공식 구현에서는 WMT16 데이터를 기반으로 각 모델별 최적 레이어를 미리 지정해두고 사용한다.
Greedy matching vs Optimal matching
- BERTScore는 계산 효율성을 위해 Greedy 방식을 사용한다. [[MoverScore]]처럼 WMD 기반의 Optimal Matching을 사용할 수도 있으나, 논문은 Greedy 방식만으로도 인간의 평가와 충분히 높은 상관관계를 보임을 입증했다.
Baseline Rescaling
- 코사인 유사도 값이 좁은 구간()에 분포하는 특성을 보정하기 위해, 랜덤 문장 쌍을 이용한 하한선()을 구하여 스코어를 범위로 선형 변환한다.
Connections
- [[BLEU]] — n-gram 기반 어휘 일치 메트릭의 대표적 한계 사례
- [[MoverScore]] — 유사한 임베딩 기반이나 Optimal Matching(WMD)을 채택
- [[METEOR]] — 의미적 유사성을 반영하려 했던 초기 시도 (Synonym fallback)
- @zhangBERTScoreEvaluatingText2020 — 원본 논문
- TF-IDF(Term Frequency-Inverse Document Frequency) — BERTScore의 IDF 가중치가 차용하는 어휘 중요도 개념.
- Spearman 순위상관계수 — metric 점수와 사람 평가의 순위 일관성으로 BERTScore 품질을 검증한다.
Discussion
Comments
댓글은 승인 후 공개됩니다.