TL;DR
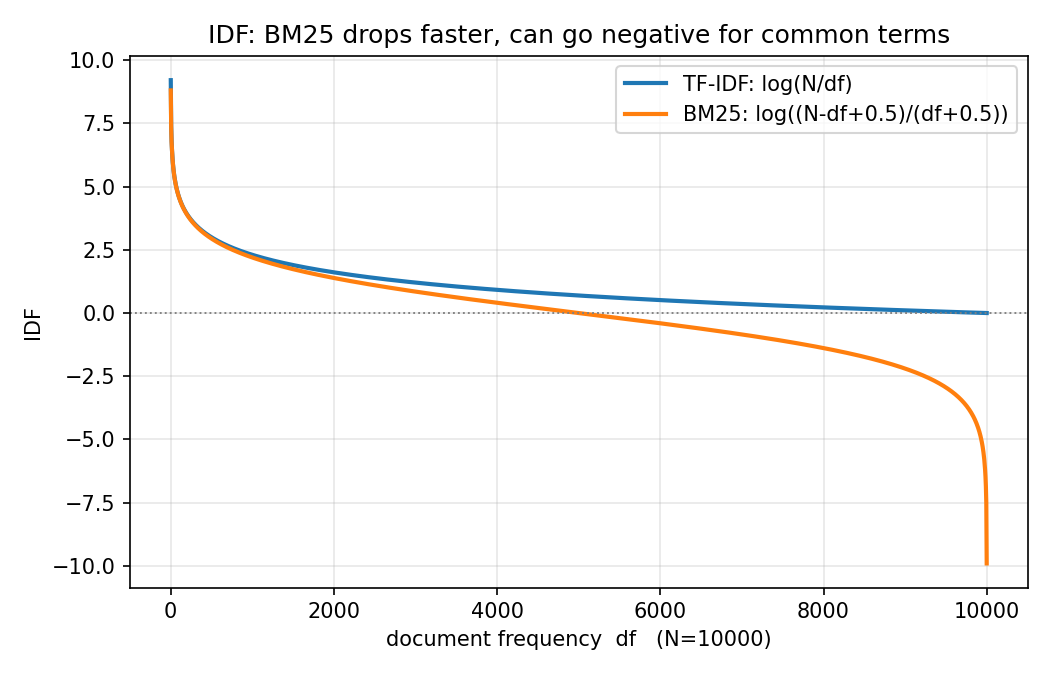
- 대표적인 sparse retrieval 알고리즘으로 TF-IDF, BM25 가 있다.
- TF-IDF 의 variation 인 BM25 는 문서 길이 페널티와 단어의 빈도 영향도를 제한한다.
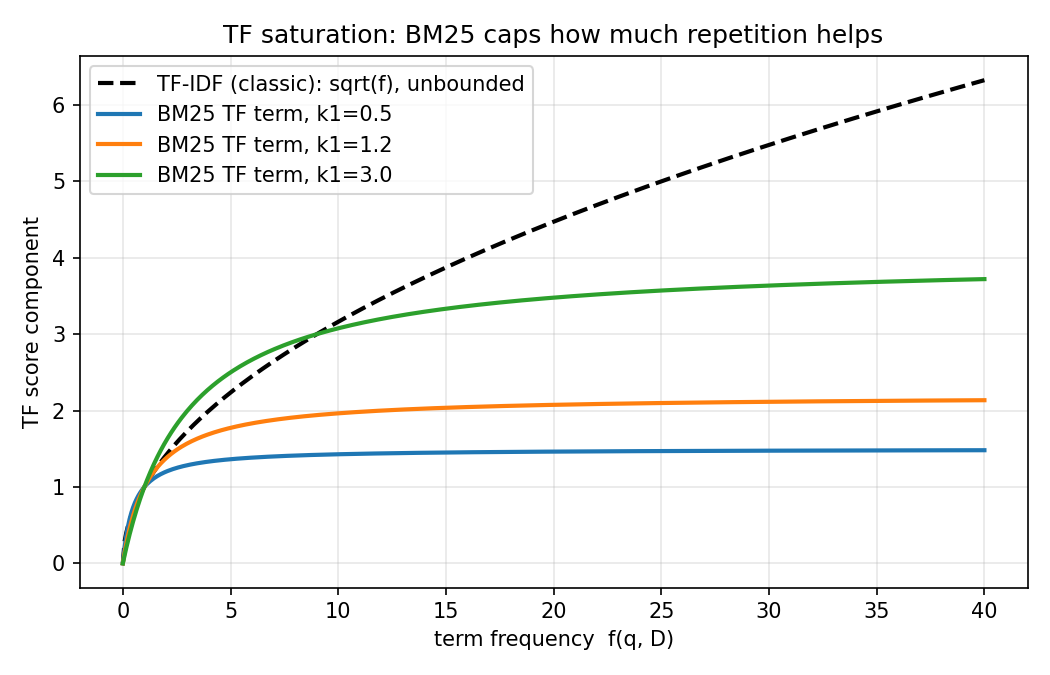
- 단어 빈도의 영향도를 결정하는 파라미터는 으로 특정 빈도수 이후 단어의 빈도수는 영향을 거의 끼치지 않는다.(saturation)
- 이 커질수록 단어의 빈도수 영향도가 커진다.
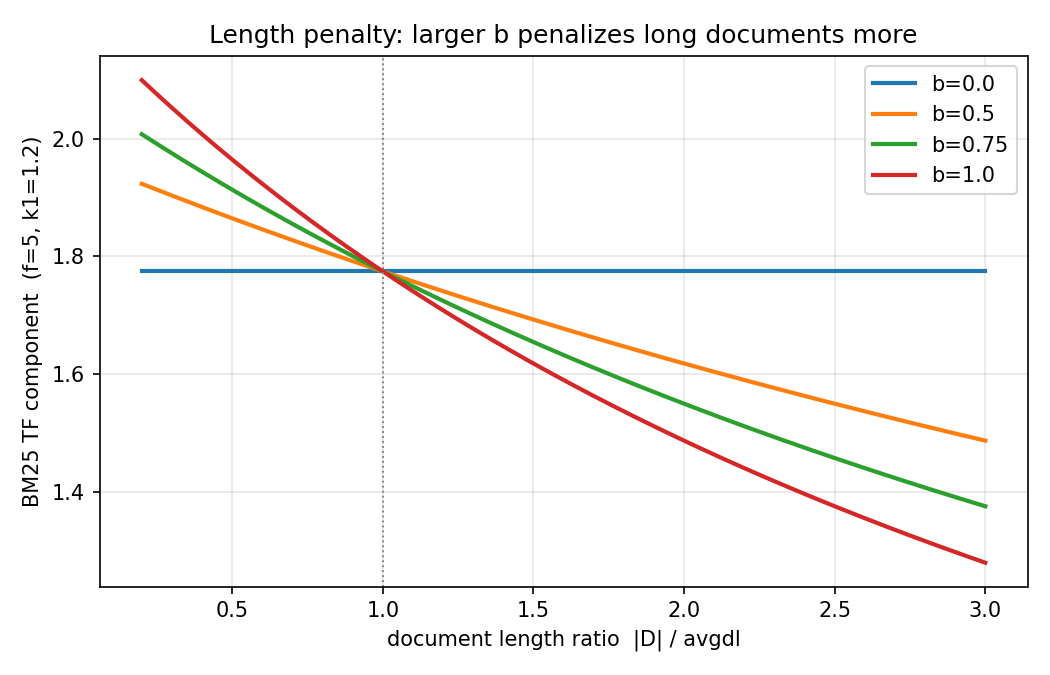
- 평균 문서 길이 대비 특정 문서 길이 비율() 로 문서길이 페널티 정도를 결정하는 파라미터는 로 커질수록 페널티를 더 많이 부여한다.
BM25
대표적인 sparse retrieval 방식에는 TF-IDF 와 BM25 가 있다. 두 알고리즘의 공통점과 차이점을 정리해보자.
점수 함수
TF-IDF 의 variation 으로 를 계산하지만 에 hyperparameter를 도입하여 발전시킨 랭킹 알고리즘이다. query , document 라 했을때, BM25 score는 다음과 같다.
하나씩 의미를 살펴보면,
- : 특정 단어(쿼리 의 번째 토큰 )가 나타난 문서의 수()가 클수록 작아지는 값이다(BM25는 보통 기반의 확률적 IDF를 쓴다). 단어가 등장한 문서 수가 많아질수록 TF-IDF의 IDF보다 더 강하게 페널티를 준다.
- : 특정 문서 내 발생한 토큰(쿼리 의 i번째 토큰 ) 의 빈도수
- (saturation parameter) : 의 경우 분모,분자에 둘 다 위치하게 되는데 이는 단일 쿼리 단어가 해당 문서의 점수에 영향을 줄 수 있는 정도를 제한 한다. 즉, 특정 빈도수를 넘어가면 빈도수는 점수에 많은 영향을 끼치지 않는다. (= saturation curve) 디폴트로 를 사용하고 값이 커질수록 단어 빈도수의 영향을 더 많이 반영하게 된다 (=덜 제한하게 된다.)
- : 특정 문서 의 길이 를 평균 길이 로 나눈 것으로 평균 대비 긴 문서는 페널티 를 준다. 구체적으로, 평균 대비 긴 문서는 값이 커지므로 분모값이 커짐에 따라 score 가 작아져 페널티를 준다.
- : 로 디폴트로 를 사용하고 1에 가까울 수록 평균 대비 문서 길이가 점수에 영향 을 끼치게 되고, 0에 가까울수록 영향을 무시 한다.
TF-IDF vs BM25
| TF-IDF | BM25 | |
|---|---|---|
| TF | 단어가 많이 등장할수록 점수가 높아진다. | 특정 빈도수 이후 단어의 빈도수 영향도는 saturate |
| IDF | 단어가 등장하는 문서가 많아질수록(=덜 중요한 단어) 점수는 낮아지지만, 특정 문서 빈도수 이후의 IDF는 saturate | 단어가 등장하는 문서가 많아질수록(=덜 중요한 단어) IDF는 많은 점수 하락 |
구현
# pip install rank_bm25
from rank_bm25 import BM25Okapi
# 두 개의 문서
documents = [
"나는 사과를 좋아합니다. 맛있는 사과를 찾고 있어요.",
"바나나는 맛있지만 사과는 더 좋아요."
]
# 문서를 토큰화
tokenized_documents = [doc.split() for doc in documents]
# BM25 모델 초기화
bm25 = BM25Okapi(tokenized_documents)
# 쿼리
query = "사과 맛있는"
# 쿼리를 토큰화
tokenized_query = query.split()
# BM25 유사도 계산
doc_scores = bm25.get_scores(tokenized_query)
# array([doc_score1,doc_score2,...]) shape = (1,|doc|)
top_n = bm25.get_top_n(tokenized_query, documents, n=3)
# [top_1_doc,top_2_doc,...] shape = (1,n)
Connections
- TF-IDF(Term Frequency-Inverse Document Frequency) — BM25가 확장한 기반 sparse retrieval 스코어링.
Discussion
Comments
댓글은 승인 후 공개됩니다.