TL;DR
- MAPE는 절대 오차를 실제값으로 나눈 뒤 평균낸 상대 오차 메트릭이다.
- 스케일 독립적으로 해석하기 쉽지만, 실제값이 0 또는 0에 가까울 때 값이 크게 흔들린다.
MAPE
MAPE(Mean Absolute Percentage Error)는 각 예측 오차를 실제값 크기로 나누어 평균낸다.
구현에서는 인 항을 제외하거나 작은 을 더해 분모를 보호한다.
nz = np.abs(true) > 1e-6
mape = (np.abs(pred - true) / np.abs(true))[nz].mean()일반 정의
MAPE는 “평균적으로 실제값 대비 몇 퍼센트 틀렸는가”를 표현한다. 서로 다른 스케일의 시계열을 비교하기 쉬워 보이지만, 분모가 각 시점의 실제값이기 때문에 작은 실제값이 평가를 지배할 수 있다.
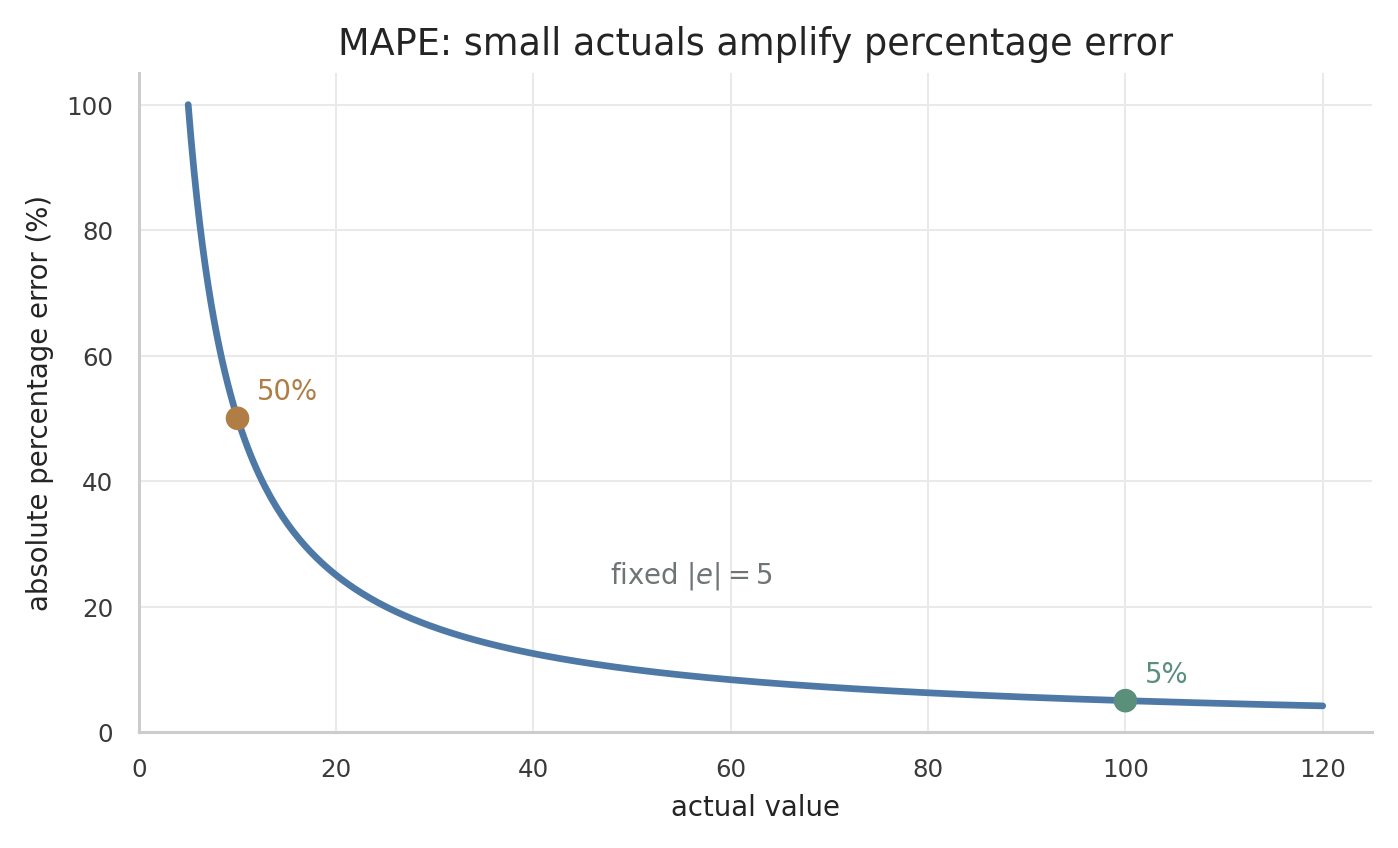
수식상 MAPE는 가중치를 갖는다. 따라서 실제값이 작은 시점의 오차는 실제값이 큰 시점의 같은 절대 오차보다 훨씬 크게 반영된다.
정확도처럼 보고할 때
일부 보고에서는 MAPE를 1 - MAPE로 뒤집어 “예측 정확도”처럼 표현한다. 별도의 오차 구조를 가진 새 메트릭이 아니라 보고 스케일 변환이며, MAPE의 한계를 그대로 상속한다. 상세는 1-MAPE 참고.
일반 시계열에서의 사용
- 타깃이 양의 수량이고, 실제값 대비 비율 오차가 의미 있는 경우에만 자연스럽다.
- 온도처럼 임의 원점을 가진 값이나 0·음수가 자주 등장하는 시계열에는 부적절할 수 있다.
- 작은 실제값이 평가를 지배할 수 있으므로, 일반 시계열 비교에서는 MAE, WAPE, scaled error와 함께 확인해야 한다.
수요 예측에서의 사용
- 판매량 규모가 다른 상품을 상대 오차 관점에서 비교할 때 유용하다.
- 작은 실제값이 많은 sparse demand, intermittent demand, 저판매량 SKU에서는 불안정하다.
- right-skewed(오른쪽 꼬리가 긴) 소매 수요에서는 낮은 quantile 예측이 작은 실제값 구간의 과대예측을 줄여 MAPE를 낮출 수 있다. 이 경우 전체 예측량은 실제 수요보다 낮아져 Forecast Bias가 음수가 될 수 있다.
예를 들어 어떤 SKU에서 실제값이 1이고 오차가 1이면 해당 관측치의 percentage error는 100%다. 반면 실제값이 100이고 오차가 10이면 10%다. 절대 오차는 두 번째가 더 크지만, MAPE에서는 작은 실제값을 가진 첫 번째 관측치가 더 크게 반영된다.
한계
- 이면 정의되지 않는다.
- 가 작으면 몇 개 차이도 매우 큰 퍼센트 오차가 된다.
- 평균 MAPE가 실제값이 매우 작은 관측치 몇 개에 크게 좌우될 수 있다.
- 1-MAPE로 정확도처럼 표현하면 음수 “정확도”가 나올 수 있다.
Connections
- WAPE — 행별 퍼센트 평균 대신 전체 절대 오차 합을 전체 실제값 합으로 나눈다.
- MAE — 원래 단위의 평균 절대 오차.
- Pinball Loss — 낮은 quantile 선택은 작은 실제값 구간의 과대예측을 줄일 수 있지만 bias trade-off가 생긴다.
- SKU (Stock Keeping Unit) — MAPE가 불안정해지기 쉬운 저판매량 상품 단위.
Discussion
Comments
댓글은 승인 후 공개됩니다.