TL;DR
- 분산은 값들이 평균 주변에서 얼마나 퍼져 있는지를 측정한다.
- 각 값과 평균의 차이를 제곱해서 평균내므로 항상 0 이상이다.
- 값이 클수록 데이터가 평균에서 멀리 흩어져 있다.
분산
분산(variance)은 하나의 변수가 자기 평균 주변에서 얼마나 흔들리는지를 나타낸다. 핵심 질문은 간단하다.
데이터 값들이 평균 근처에 모여 있는가, 아니면 평균에서 멀리 퍼져 있는가?
값들이 평균 근처에 모여 있으면 분산은 작다. 값들이 평균에서 멀리 떨어져 있으면 분산은 크다.
직관
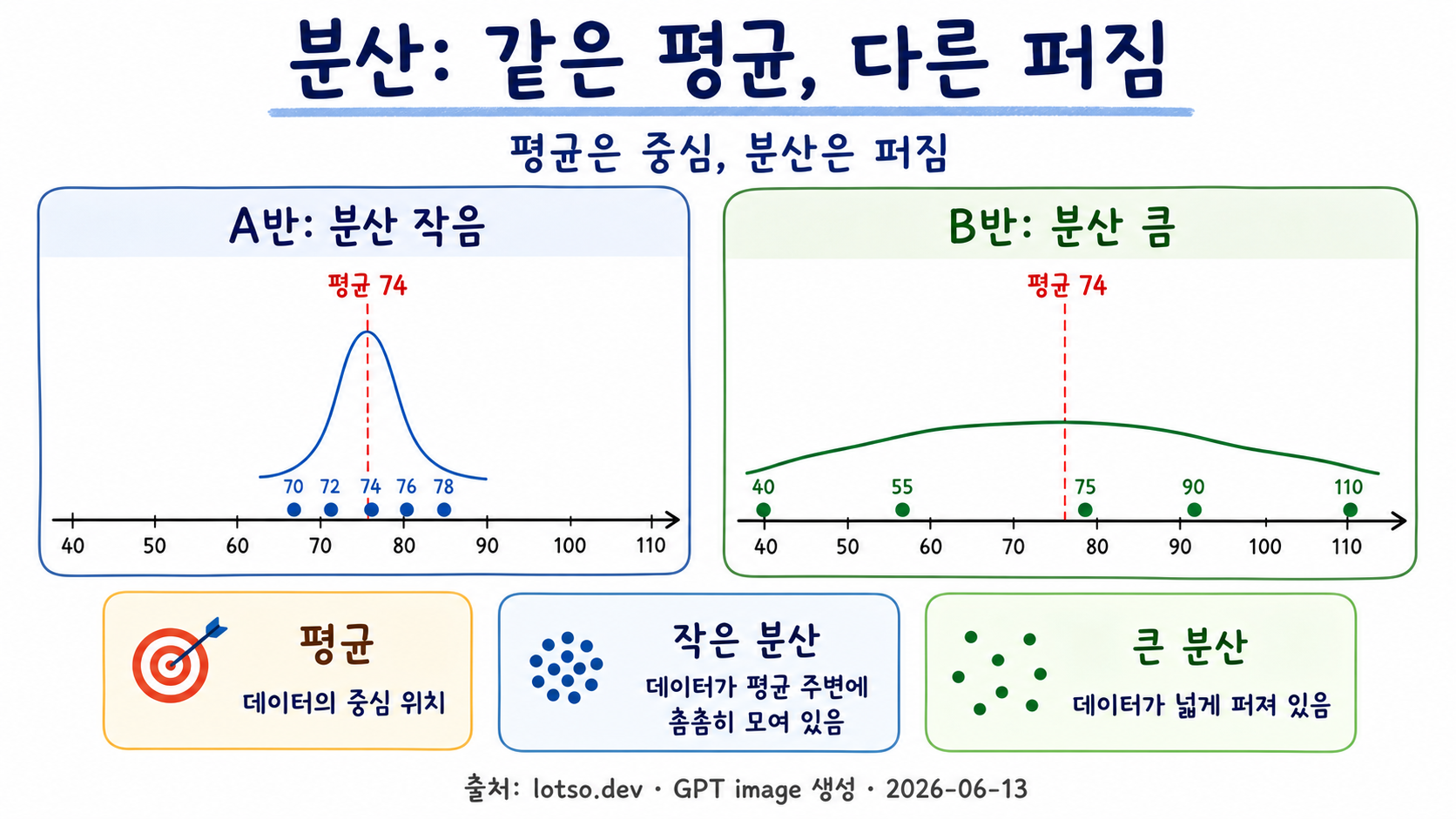
두 반의 시험 점수를 비교해보자.
| 반 | 점수 |
|---|---|
| A반 | 70, 72, 74, 76, 78 |
| B반 | 40, 55, 75, 90, 110 |
두 반의 평균이 비슷하더라도, A반은 점수가 평균 근처에 모여 있고 B반은 점수가 넓게 퍼져 있다. 이때 B반의 분산이 더 크다.
분산은 “평균에서 얼마나 떨어졌는가”를 모아 보는 값이다.
왜 제곱하는가
각 값에서 평균을 빼면 평균보다 큰 값은 양수, 평균보다 작은 값은 음수가 된다.
그 차이를 그냥 더하면 양수와 음수가 서로 상쇄된다. 그래서 분산은 차이를 제곱한다.
제곱을 하면 두 가지 효과가 생긴다.
- 평균보다 크든 작든 떨어진 정도가 양수로 누적된다.
- 평균에서 멀리 떨어진 값은 더 크게 반영된다.
수식
모집단 전체를 알고 있을 때의 모분산은 다음과 같다.
표본으로 모집단의 분산을 추정할 때의 표본분산은 다음과 같다.
각 항의 의미는 다음과 같다.
- : 각 값이 표본 평균에서 얼마나 떨어져 있는지
- : 평균에서 떨어진 정도를 제곱한 값
- : 모든 관측치의 제곱 편차를 합산
- : 표본 평균을 사용해 모집단 분산을 추정할 때의 보정
표준편차와의 관계
분산은 제곱 단위를 갖는다. 예를 들어 키를 cm로 측정했다면 분산의 단위는 가 된다. 이 단위는 직관적으로 읽기 어렵다.
그래서 분산의 제곱근을 취한 표준편차를 자주 사용한다.
표준편차는 원래 데이터와 같은 단위를 가지므로 해석하기 쉽다. 다만 계산의 기본 구조는 분산이 담당한다.
공분산과의 관계
분산은 한 변수의 퍼짐을 측정한다. 공분산은 두 변수가 평균 기준으로 함께 움직이는지를 측정한다.
분산은 공분산의 특수한 경우로 볼 수 있다.
즉, 어떤 변수와 자기 자신의 공분산이 바로 그 변수의 분산이다.
이 관계 때문에 공분산 행렬의 대각 원소는 각 변수의 분산이고, 비대각 원소는 변수 쌍 사이의 공분산이다.
주의할 점
이상치에 민감하다
분산은 평균과 제곱 편차를 사용하므로 이상치에 민감하다. 평균에서 멀리 떨어진 값은 제곱 때문에 매우 크게 반영된다.
표본분산과 모분산의 분모가 다르다
모집단 전체를 계산하면 으로 나누고, 표본으로 모집단 분산을 추정할 때는 보통 로 나눈다. NumPy에서는 np.var(x)의 기본값이 ddof=0이므로 모분산 형태이고, 표본분산은 np.var(x, ddof=1)로 계산한다.
구현
import numpy as np
x = [70, 72, 74, 76, 78]
population_var = np.var(x)
sample_var = np.var(x, ddof=1)Connections
- 공분산 — 두 변수의 평균 기준 동반 움직임을 측정한다.
- 공분산 행렬 — 여러 변수의 분산과 공분산을 행렬로 모은 구조.
- 표준편차 — 분산의 제곱근. 원래 데이터와 같은 단위를 갖는다.
- [[주성분 분석]] — 데이터의 분산이 큰 방향을 찾는 차원 축소 방법.
Discussion
Comments
댓글은 승인 후 공개됩니다.