Zotero History
- Date item added to Zotero:: 2024-12-03
- First date annotations or notes modified:: 2026-03-29
- Last date annotations or notes modified:: 2026-04-12
- Export date:: 2026-04-12
BERTScore: Evaluating Text Generation with BERT
Cite
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020). BERTScore: Evaluating Text Generation with BERT (arXiv:1904.09675). arXiv. https://doi.org/10.48550/arXiv.1904.09675
TL;DR
Contribution:: BERT contextual embedding 기반의 text generation 자동 평가 메트릭. n-gram exact match 대신 token-level cosine similarity로 의미적 유사성 평가
Pros:: 363개 시스템에서 human judgment과 높은 상관관계. task-agnostic (MT, captioning). 104개 언어 지원. 외부 리소스 불필요
Cons:: max_length 제한(BERT=512)으로 문서 수준 평가 부적합. 사실 오류(factual error) 탐지 불가. 모델/레이어/IDF 설정에 따라 성능 변동
Study Snapshot
Key takeaway:: contextual embedding + greedy matching으로 기존 n-gram 메트릭의 패러프레이즈/동의어 매칭 한계를 해결. 단, faithfulness 평가에는 부적합
Methods:: (1) Reference/Candidate를 BERT에 통과시켜 contextual embedding 추출 (2) token 쌍 cosine similarity 행렬 생성 (3) greedy matching: Recall=row-wise max, Precision=column-wise max (4) optional IDF 가중 평균 (5) F1 = 2PR/(P+R)
Outcomes:: WMT18 system-level: 대부분 언어쌍에서 BLEU, METEOR, YiSi-1 압도. Segment-level: RUSE(supervised)도 능가. Image captioning: task-specific SPICE보다 우수
Results:: PAWS 적대적 예제에서 다른 메트릭은 chance 수준 하락, BERTScore는 소폭 하락만. 중간 레이어가 최적(Appendix B). WMD optimal matching 교체 시 일관된 개선 없음(Appendix C)
Implementations
- 공식 구현: Tiiiger/bert_score
- korean: lovit/KoBERTScore
Meta
Author:: Zhang, Tianyi
Author:: Kishore, Varsha
Author:: Wu, Felix
Author:: Weinberger, Kilian Q.
Author:: Artzi, YoavTitle:: BERTScore: Evaluating Text Generation with BERT
Short Title::BERTScore Year:: 2020Citekey:: @zhangBERTScoreEvaluatingText2020
itemType:: preprintDOI:: 10.48550/arXiv.1904.09675
LINK
Abstract
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact matches, we compute token similarity using contextual embeddings. We evaluate using the outputs of 363 machine translation and image captioning systems. BERTScore correlates better with human judgments and provides stronger model selection performance than existing metrics. Finally, we use an adversarial paraphrase detection task to show that BERTScore is more robust to challenging examples when compared to existing metrics.
Reading notes
🔴 Problems
Highlight (1 page, edited: [[2026-04-12]])
n-gram overlap between the candidate and the reference. While this provides a simple and general measure, it fails to account for meaning-preserving lexical and compositional diversity.
Problems:
n-gram overlap 기반 메트릭(BLEU)의 근본적 한계 — 의미를 보존하는 어휘적·구성적 다양성을 반영하지 못함
“consumers prefer imported cars”와 “people like foreign cars”가 의미적으로 동일하더라도 표면 형태가 다르면 낮은 점수
BERTScore 설계의 핵심 동기
Highlight (1 page, edited: [[2026-04-12]])
This leads to performance underestimation when semantically-correct phrases are penalized because they differ from the surface form of the reference.
Problems:
의미적으로 올바른 번역이 reference와 표면 형태가 다르다는 이유로 과소평가됨
exact match 방식의 구조적 한계: 동의어, 패러프레이즈를 포착 불가
이 문제가 BERTScore에서 contextual embedding + cosine similarity로 대체되는 직접적 동기
Highlight (1 page, edited: [[2026-04-12]])
Second, n-gram models fail to capture distant dependencies and penalize semantically-critical ordering changes (Isozaki et al., 2010).
Problems:
n-gram 모델의 두 번째 한계: 원거리 의존성 포착 실패 + 의미적으로 중요한 어순 변화에 대한 페널티 부족
예: “A because B”와 “B because A”를 window=2인 BLEU가 거의 구분하지 못함
contextual embedding은 self-attention으로 unbounded dependency를 포착하여 해결
🟡 Prior Research
Highlight (2 page, edited: [[2026-04-12]])
METEOR (Banerjee & Lavie, 2005) computes Exact-P1 and Exact-R1 while allowing backing-off from exact unigram matching to matching word stems, synonyms, and paraphrases.
Prior Research:
METEOR의 접근: exact match 실패 시 stem/synonym/paraphrase로 fallback
외부 리소스(stemmer, synonym lexicon, paraphrase table)에 의존
5개 언어만 전체 지원, 11개는 부분 지원 → BERTScore는 BERT 104개 언어 활용
Highlight (3 page, edited: [[2026-04-12]])
All these methods require costly human judgments as supervision for each dataset, and risk poor generalization to new domains, even within a known language and task
Prior Research:
학습 기반 메트릭(BEER, BLEND, RUSE)의 한계
각 데이터셋마다 비싼 human judgment 필요
동일 언어·태스크 내에서도 새 도메인으로 일반화 위험
BERTScore는 특정 evaluation task에 최적화하지 않으므로 이 문제 회피
Highlight (3 page, edited: [[2026-04-12]])
However, we use contextual embeddings, which capture the specific use of a token in a sentence, and potentially capture sequence information.
Prior Research:
기존 embedding 기반 메트릭(MEANT 2.0, YiSi-1)과의 차별점
static word embedding은 문맥 무관한 단일 벡터 → contextual embedding은 문맥에 따라 다른 벡터
외부 linguistic structure(semantic parse) 불필요 → 언어 이식성 우수
🔵 Main Idea
Highlight (1 page, edited: [[2026-04-12]])
In this paper, we introduce BERTSCORE, a language generation evaluation metric based on pretrained BERT contextual embeddings (Devlin et al., 2019)
Main Idea:
핵심 제안: pretrained BERT contextual embedding 기반의 text generation 자동 평가 메트릭
task-agnostic: MT, image captioning 등 여러 생성 태스크에 범용 적용
363개 시스템 출력으로 평가, human judgment과 높은 상관관계 입증
Highlight (1 page, edited: [[2026-04-12]])
BERTSCORE computes the similarity of two sentences as a sum of cosine similarities between their tokens’ embeddings.
Main Idea:
한 줄 요약: token-level contextual embedding 간 cosine similarity의 합으로 두 문장의 유사도 계산
exact match 대신 soft similarity → 패러프레이즈, 동의어 자연스럽게 처리
greedy matching으로 각 토큰을 상대 문장의 가장 유사한 토큰에 매칭
Image (4 page, edited: [[2026-04-12]])
Main Idea:
- candidate 와 reference 를 BERT에 태워 contextual embedding 값을 얻어내고, token-pair 마다 cosine similarity 이용하여 유사성을 평가하고 IDF로 각 token에 가중치를 부여.
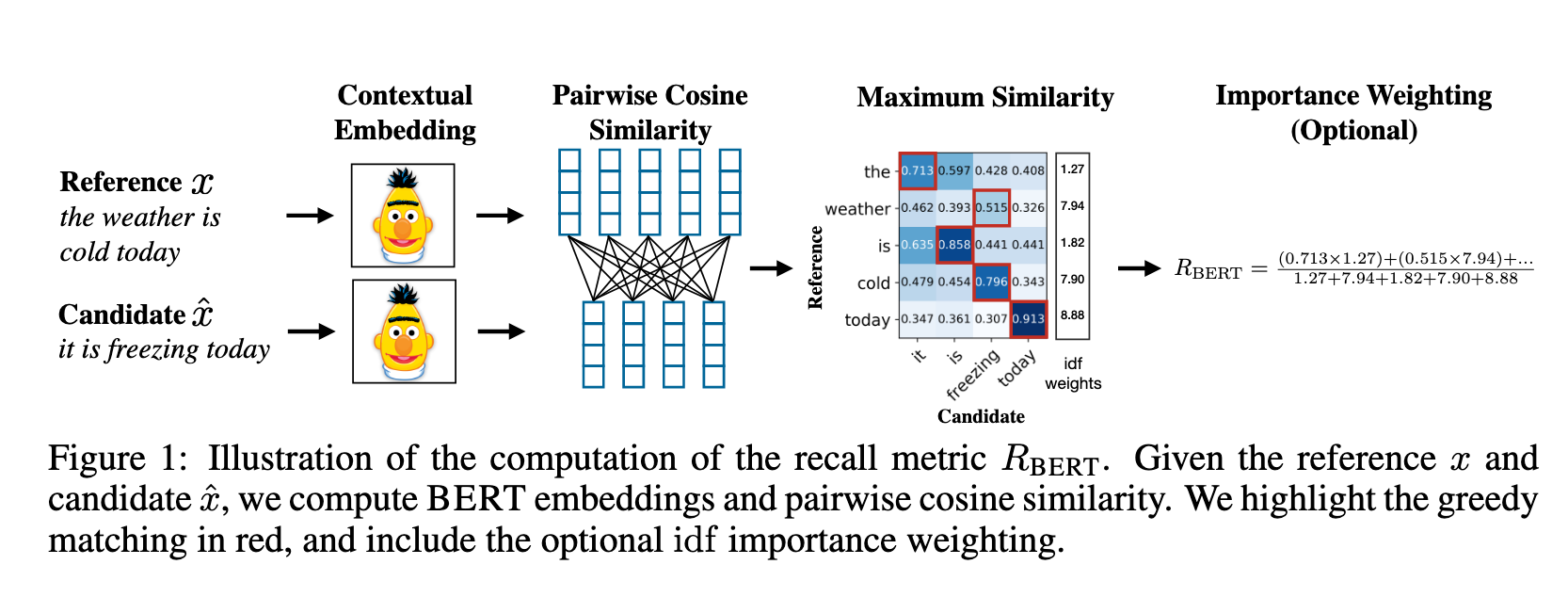
🟢 Methods
Highlight (4 page, edited: [[2026-04-12]])
We combine precision and recall to compute an F1 measure.
Methods:
Recall: reference의 각 토큰을 candidate에서 greedy matching (row-wise max)
Precision: candidate의 각 토큰을 reference에서 greedy matching (column-wise max)
F1이 대부분의 설정에서 가장 안정적인 메트릭
Image (4 page, edited: [[2026-04-12]])
BERTScore recall : row-wise max pooling
BERTScore precision: column-wise max pooling
(optional) : 개의 reference 문장들을 보면서 토큰이 reference 문장에 들어가면 1, 아니면 0으로 카운팅 후 평균값(로그스케일)

Highlight (4 page, edited: [[2026-04-12]])
BERTSCORE enables us to easily incorporate importance weighting. We experiment with inverse document frequency (idf) scores computed from the test corpus.
Methods:
IDF 가중치 적용:
개 reference 문장에서 토큰 출현 빈도의 역수(로그 스케일)
tf는 단일 문장이므로 1로 가정, idf만 사용
희귀 토큰에 높은 가중치 → 문장 유사도에 더 큰 기여
Image (5 page, edited: [[2026-03-29]])
cosine-similarity로 score를 계산했기 때문에 bound가 이지만,저자들이 실제로 계산 시에는 (-1,+1)보다 작은 구간에서 값들이 형성. (초고차원에서 -1,1 에 가까운 값을 갖기에는 매우 어려움)
따라서 저자들은 score의 readability를 높히기 위해 실증적인 lower-bound 를 찾아 실제 계산 score가 (-1,+1) 사이로 오도록 rescaling을 진행.

🟠 Limitations
Highlight (7 page, edited: [[2026-04-12]])
Overall, we find that applying importance weighting using idf at times provides small benefit, but in other cases does not help. Understanding better when such importance weighting is likely to help is an important direction for future work, and likely depends on the domain of the text and the available test data. We continue without idf weighting for the rest of our experiments.
Limitations:
IDF weighting의 효과가 불일관
일부 설정에서만 소폭 개선, 다른 경우에는 도움 안 됨
도메인·테스트 데이터에 따라 달라지며, 이를 이해하는 것이 future work
이후 실험에서는 IDF 없이 진행
Highlight (9 page, edited: [[2026-04-12]])
However, there is no one configuration of BERTSCORE that clearly outperforms all others.
Limitations:
모든 설정에서 최적인 단일 구성은 없음
모델 선택(BERT vs RoBERTa vs multilingual), 레이어, IDF 사용 여부 등이 도메인/언어에 따라 다름
영어: RoBERTa-large 24-layer 권장
비영어: multilingual BERT 사용 가능하나 저자원 언어에서 불안정
🟣 Key Concepts to Clarify
Highlight (3 page, edited: [[2026-04-12]])
Instead of greedy matching, WMD (Kusner et al., 2015), WMDO (Chow et al., 2019), and SMS (Clark et al., 2019) propose to use optimal matching based on earth mover’s distance (Rubner et al., 1998).
Key Concepts to Clarify:
Greedy matching vs Optimal matching
Greedy: 각 토큰을 가장 유사한 상대 토큰에 1:1 매칭 → , 단순하고 빠름
Optimal (EMD/WMD): 전체 최적 할당 → 계산 비용 높음
BERTScore는 greedy 선택 — Appendix C에서 optimal 대비 일관된 개선 없음을 확인
MoverScore는 같은 맥락에서 optimal(WMD) 선택
Highlight (4 page, edited: [[2026-04-12]])
In contrast to prior word embeddings (Mikolov et al., 2013; Pennington et al., 2014), contextual embeddings, such as BERT (Devlin et al., 2019) and ELMO (Peters et al., 2018), can generate different vector representations for the same word in different sentences depending on the surrounding words, which form the context of the target word.
Key Concepts to Clarify:
Contextual embedding vs static embedding의 핵심 차이
Static (Word2Vec, GloVe): 단어당 하나의 고정 벡터
Contextual (BERT, ELMo): 같은 단어도 주변 문맥에 따라 다른 벡터 생성
Transformer의 self-attention이 문맥 정보를 인코딩 → 다의어, 어순 변화 포착 가능
🟪 Results
Image (7 page, edited: [[2026-04-12]])
Results:
[Table 4 분석] Segment-level 성능:
BERTScore가 모든 메트릭 대비 유의하게 높은 성능
BLEU 대비 특히 큰 개선 — 개별 문장 분석에 적합
심지어 supervised 메트릭 RUSE도 segment-level에서는 BERTScore에 열세
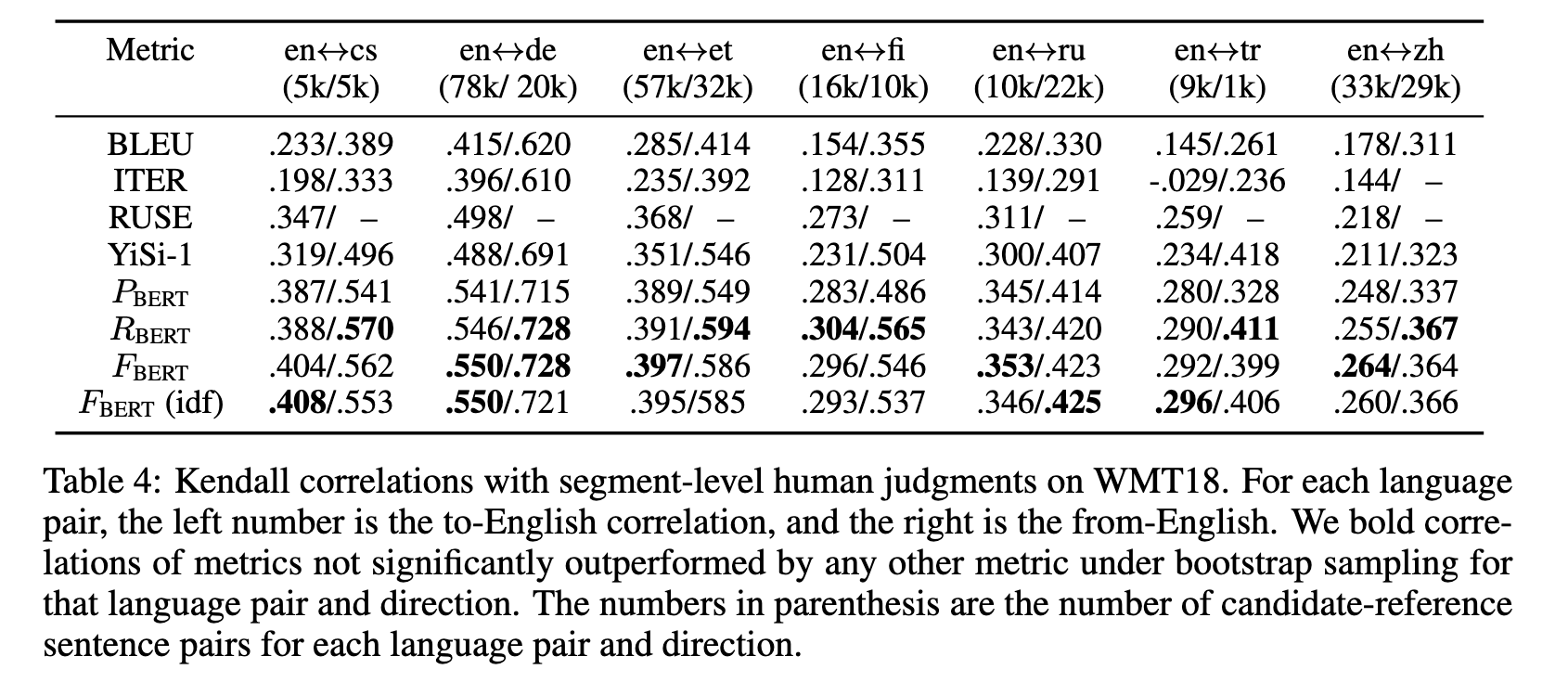
Image (8 page, edited: [[2026-04-12]])
Results:
[Table 5 분석] Image captioning (COCO 2015 Captioning Challenge) 결과:
M1: 생성 캡션이 인간 캡션 대비 better or equal로 평가된 비율
M2: 생성 캡션이 인간 캡션과 **구분 불가능(indistinguishable)**한 비율 (더 엄격)
BERTScore가 task-agnostic 메트릭 중 M1/M2 모두에서 큰 폭으로 최고 성능
BLEU, ROUGE 등 n-gram 메트릭은 human judgment와 약한 상관관계
SPICE(task-specific)보다도 우수 → 별도 task 최적화 없이도 강력한 범용성
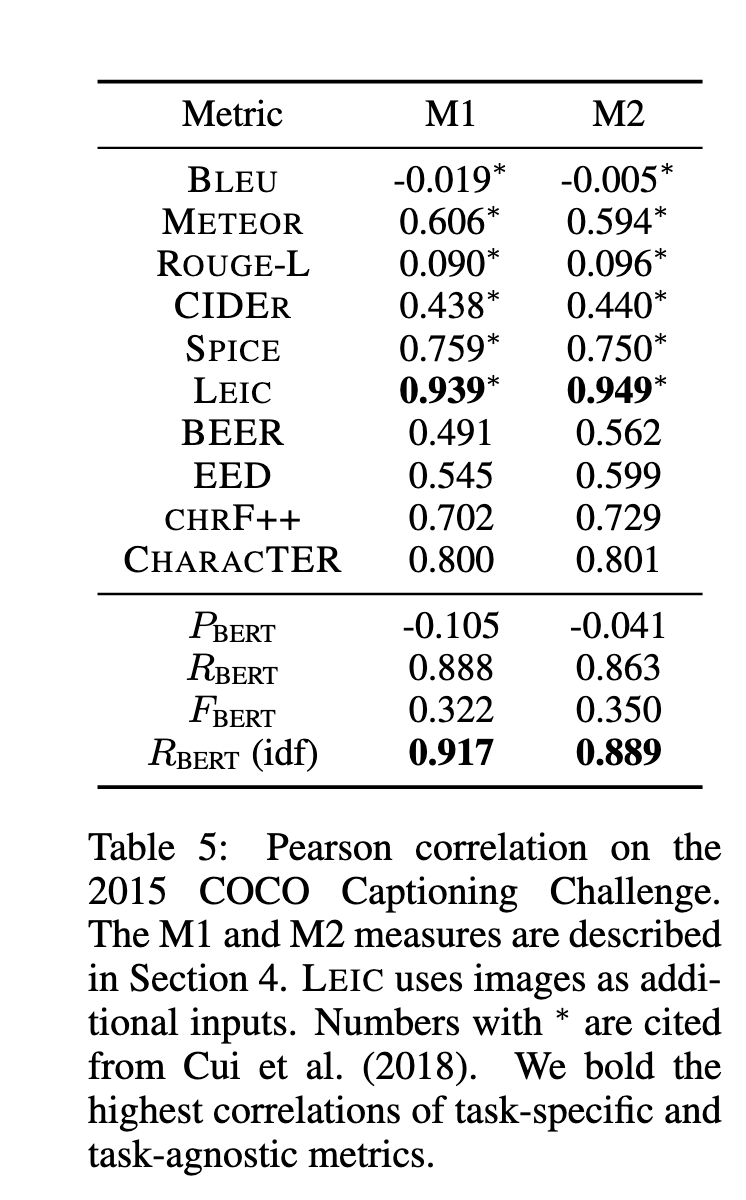
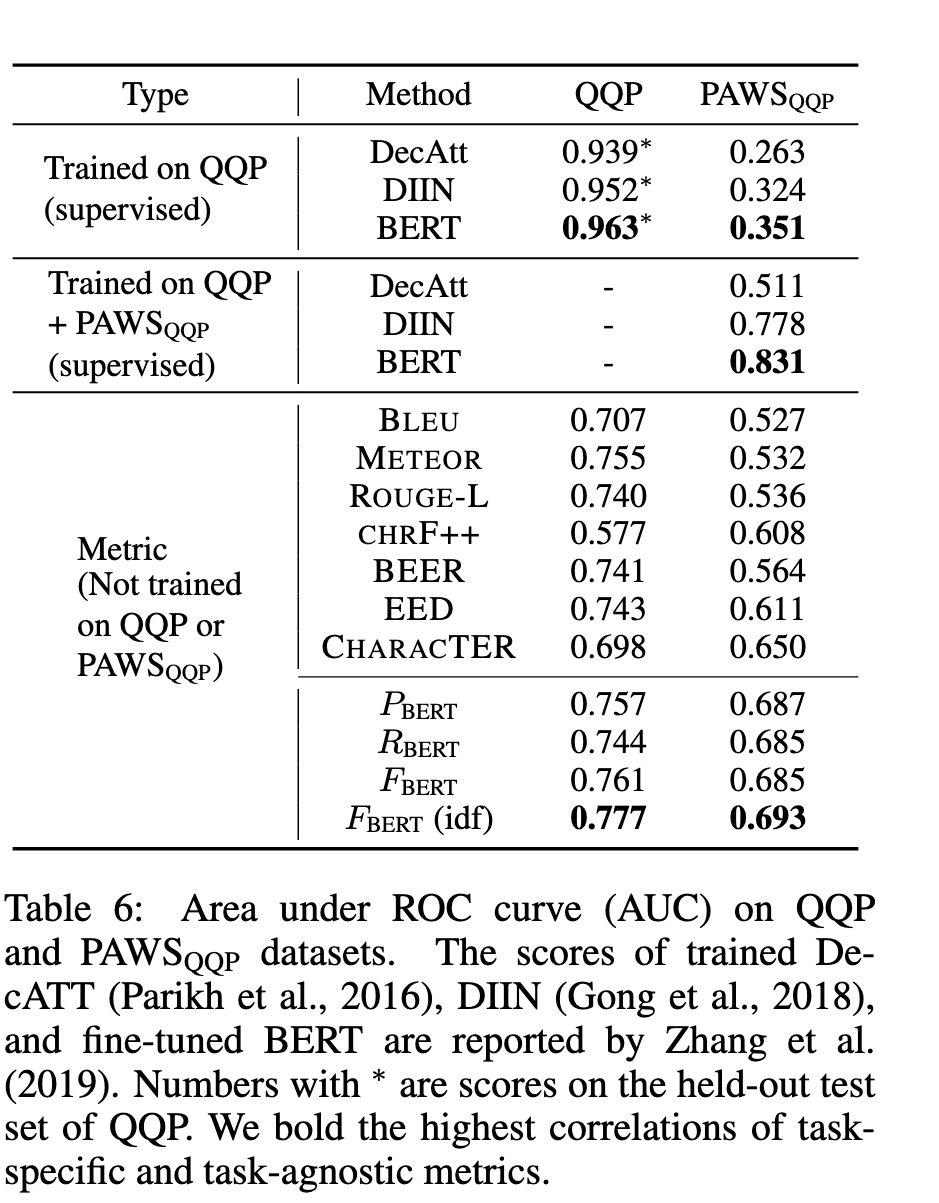
Image (8 page, edited: [[2026-04-12]])
Results:
[Table 6 분석] Adversarial robustness (PAWS):
대부분의 메트릭이 QQP에서는 적절하나 PAWS 적대적 예제에서 chance 수준까지 하락
BERTScore는 소폭 하락만 — contextual embedding이 word swapping에도 의미 차이를 포착
예: “Flights from New York to Florida” vs “Flights from Florida to New York” 구분 가능
🔘 Ablation Study
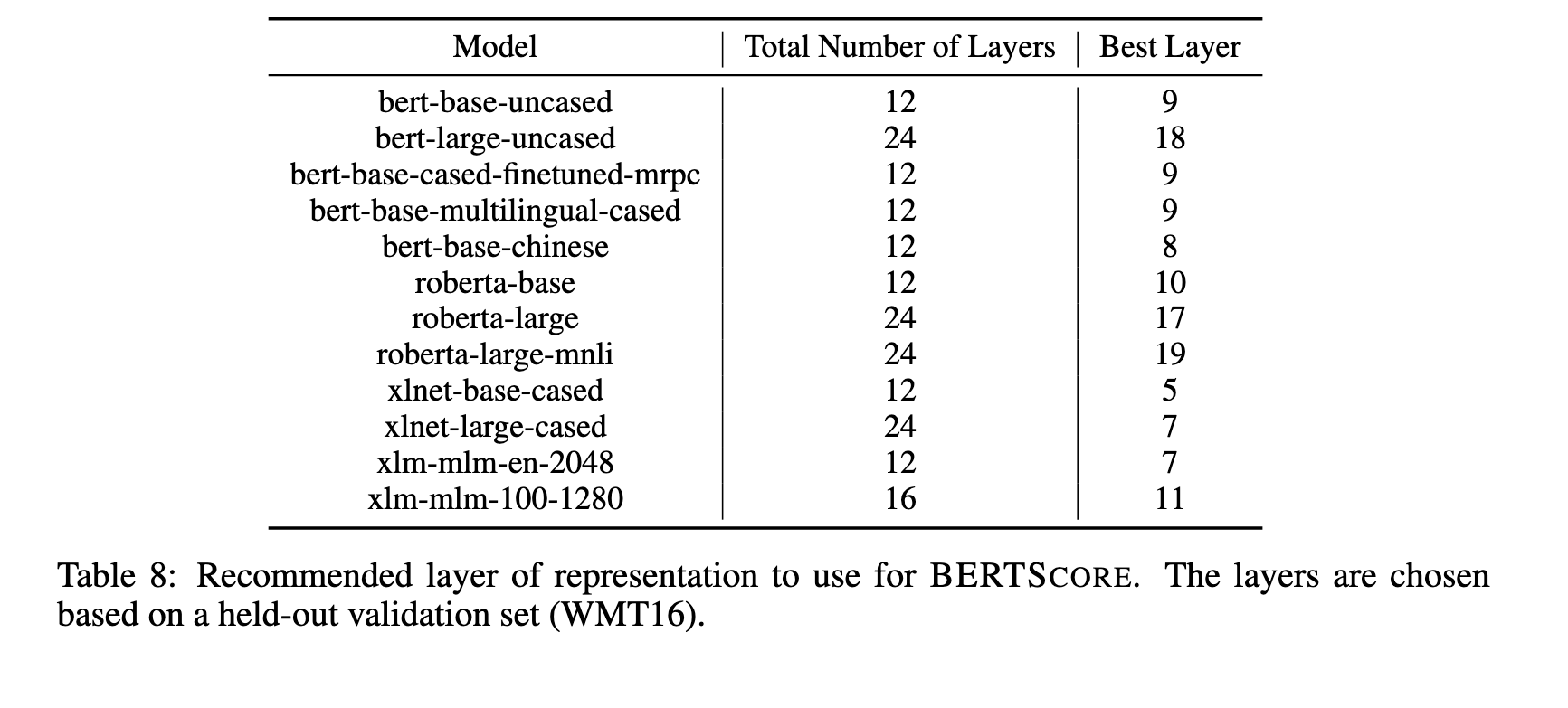
Image (16 page, edited: [[2026-04-12]])
Ablation Study:
[Appendix B] BERT 레이어 선택 실험:
모든 모델에서 중간 레이어가 최적 성능
최종 레이어는 masked language modeling 등 pretraining objective에 특화되어 semantic similarity에 덜 적합
WMT16을 validation으로 사용하여 각 모델별 최적 레이어 탐색
Highlight (19 page, edited: [[2026-04-12]])
Third, replacing greedy matching with WMD does not lead to consistent improvement.
Ablation Study:
[Appendix C] Greedy matching vs WMD(optimal) 비교:
WMD로 교체해도 일관된 개선 없음 — 오히려 BERTScore(greedy)가 동일 설정에서 더 나은 경우 다수
결론: greedy matching이 text generation 평가에 충분하며, optimal matching의 추가 계산 비용이 정당화되지 않음
MoverScore와의 핵심 차이점
Discussion
Comments
댓글은 승인 후 공개됩니다.