TL;DR
- 무엇인가: Vision-Language Model(VLM)의 부정(Negation) 이해 능력을 평가하기 위해 이미지, 비디오, 의료 도메인을 아우르는 79K 예제로 구성된 대규모 멀티모달 벤치마크.
- 왜 중요한가: 최신 VLM들이 부정 쿼리에서 무작위 추측(Chance level) 수준의 성능을 보임을 입증하여, 시각-언어 정렬의 근본적인 취약점을 드러내고 개선 방향(합성 데이터 학습 등)을 제시함.
NegBench
VLM이 “특정 객체가 없는 이미지 검색”과 같은 실용적 시나리오에서 필수적인 부정 이해 능력을 얼마나 갖추었는지 체계적으로 평가하기 위해 설계된 데이터셋이다.
1. 데이터 구조 및 구성
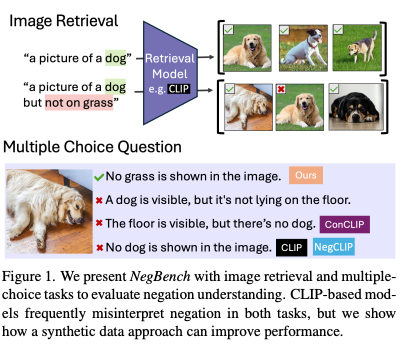
- 모달리티 / 도메인: 이미지(COCO, VOC), 비디오(MSR-VTT), 의료 이미지(CheXpert)
- 주요 태스크: Retrieval with Negation, MCQ with Negated Captions
- 구성 단위: Multiple Choice Questions(MCQ), Retrieval pairs
- 규모: 79,000 예제, 18개 태스크 변형
- 분할: 평가 중심 벤치마크 (CheXpert, COCO 등 개별 소스 필요)
| 모달리티 | 데이터 소스 | 태스크 |
|---|---|---|
| 이미지 | COCO 2017 Val, VOC2007 | MCQ, Retrieval |
| 이미지 | Synthetic (Stable Diffusion) | MCQ, Retrieval |
| 이미지 (의료) | CheXpert | Binary MCQ |
| 비디오 | MSR-VTT | MCQ, Retrieval |
2. 구축 방식

- 원천 데이터: COCO, VOC2007, CheXpert, MSR-VTT
- 구축 방법: 규칙 기반 템플릿 적용 및 Llama 3.1을 활용한 비디오 캡션 재구성(Rephrasing)
- 품질 관리: 기존 검증된 데이터셋의 캡션을 논리적으로 변환하여 신뢰도 확보
- 라이선스 / 사용 조건: MIT (코드 기준)
3. 활용과 평가
- 주요 활용: VLM의 부정어 이해도 측정 및 이를 개선하기 위한 파인튜닝 효과 검증
- 기준 성능 / 대표 결과: CLIP 등 현대 모델들이 부정 태스크에서 Chance level에 가까운 성능을 보임 (부정어를 사실상 무시)
- 특징적인 통찰:
- CC12M 기반 합성 부정 데이터로 파인튜닝 시, MCQ 정확도는 40% 이상 향상됨.
- 반면 Retrieval recall 향상은 10% 내외로, 부정 표현 이해만으로는 검색의 근본적 한계 극복에 한계가 있음.
4. 한계 및 주의점
- 범위 한계: 한국어 등 비영어 언어에 대한 평가는 미포함
- 해석 시 주의할 점: 부정 이해력 향상이 일반적인 VLM의 정렬 성능(Trade-off)에 미치는 영향 고려 필요
- 향후 과제: 이중 부정, 조건부 부정 등 더 복잡한 논리 구조로의 확장 필요
Connections
- NegConstraint — 텍스트 도메인에서의 부정 제약 관련 데이터셋
- Neuro-Symbolic IR — 부정 제약 조건을 논리적으로 해결하려는 검색 패러다임
- [[Dense Retrieval]] — 벡터 검색 모델의 주요 취약점인 구조적 질의 해결 관련
Discussion
Comments
댓글은 승인 후 공개됩니다.