TL;DR
- 무엇인가: OpenAI가 Let’s Verify Step by Step에서 held-out 평가셋으로 사용한 500개의 수학 문제 서브셋.
- 왜 중요한가: OpenAI의 “Let’s Verify Step by Step” 연구의 핵심 평가 데이터셋으로 사용되며, 모델의 수학 추론 능력을 빠르게 비교할 때 자주 사용되는 소규모 평가셋.
MATH-500
1. 데이터 구조 및 구성

- 모달리티 / 도메인: 텍스트 / 수학 (대수학, 기하학, 삼각법, 확률 등)
- 주요 태스크: Mathematical Reasoning, Chain-of-Thought
- 구성 단위: 문제(LaTeX) - 정답 매핑
- 규모: 엄선된 500개 샘플 (MATH 테스트셋에서 추린 부분집합)
2. 구축 방식
- 원천 데이터: MATH Benchmark (Hendrycks et al., 2021).
- 구축 방법: OpenAI가 Let’s Verify Step by Step 연구에서 평가용으로 분리해 사용한 500개의 held-out 문제 셋을 기반으로 한다.
- 품질 관리: 원본 MATH 벤치마크의 검증된 정답 및 풀이 과정 활용.
3. 활용과 평가
- 주요 활용: 추론 모델(O1, Qwen2.5-Math 등)의 논리적 단계 검증 및 정확도 측정.
- 기준 성능 / 대표 결과:
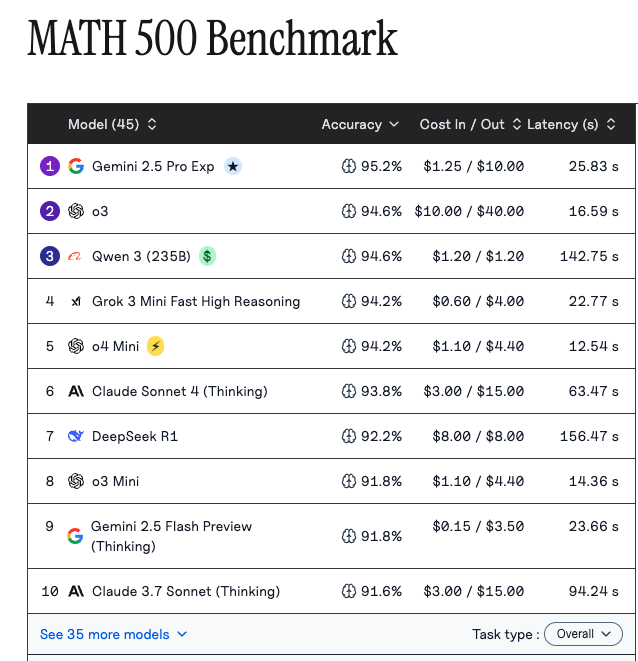
- 특징적인 통찰: 대규모 데이터셋 전체를 평가하기 부담스러운 환경에서, 모델 간의 상대적 추론 능력을 빠르게 비교할 수 있는 고신뢰성 지표로 활용됨.
4. 한계 및 주의점
- 범위 한계: 500개라는 적은 샘플 수로 인해 모델의 전체적인 수학적 일반화 성능을 완벽히 대변하기에는 한계가 있을 수 있음.
- 해석 시 주의할 점: LaTeX 형식의 응답을 파싱하는 방식에 따라 측정 점수가 달라질 수 있으므로 표준 파서를 사용하는 것이 권장됨.
Connections
- [[Chain of Thought]] — 수학 문제 풀이의 핵심 추론 기법
- [[Step-by-step Verification]] — MATH-500 평가 시 주로 활용되는 프로세스 보상 기법
Source Trail
- 원본 논문 / 데이터셋 카드: HuggingFace MATH-500
- 공식 리소스: MATH Benchmark Paper (Hendrycks et al.) | MATH GitHub
Discussion
Comments
댓글은 승인 후 공개됩니다.