TL;DR
- 무엇인가: 복수 정답을 허용하는 한국어 환각 판별 능력을 평가하기 위한 2,170개 규모의 객관식 벤치마크 데이터셋.
- 왜 중요한가: 단일 정답 위주의 기존 평가 방식과 달리, 실제 문서에서 발생할 수 있는 여러 환각 문장을 동시에 식별하는 능력을 측정하여 한국어 모델의 사실성(Factuality) 검증을 고도화함.
K-HALU
한국어 LLM의 환각(Hallucination) 현상을 정밀하게 측정하기 위해 7가지 도메인의 지문을 바탕으로 구축된 벤치마크다.
1. 데이터 구조 및 구성
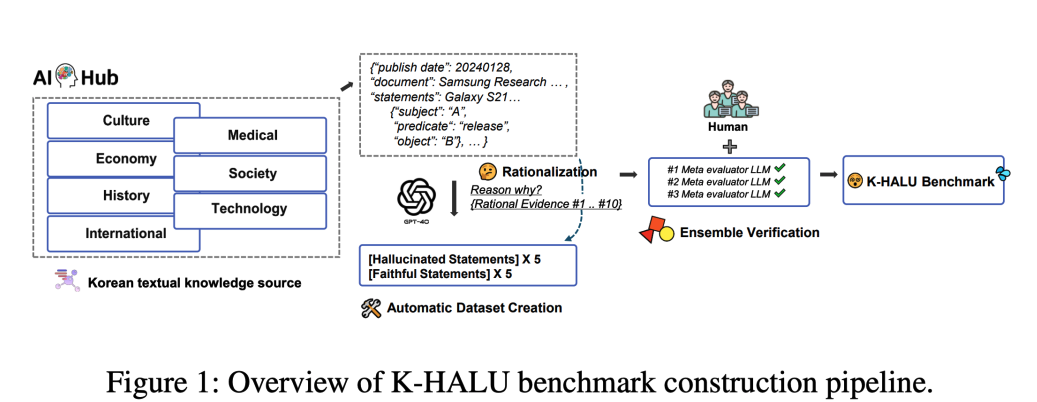
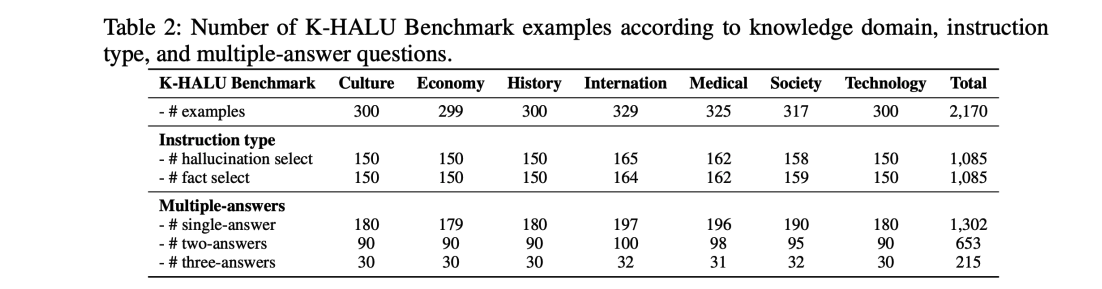
- 모달리티 / 도메인: 텍스트 / 문화, 경제, 역사, 세계, 의료, 사회, 기술 (7개 도메인)
- 주요 태스크: Hallucination Detection, Multiple Choice QA
- 구성 단위: 5지 선다형 객관식 (일부는 복수 정답 허용)
- 규모: 총 2,170개 test samples
데이터 예시 및 지시문

- 문항 구조 특징: 전체 데이터셋의 약 40%가 복수 정답 형식으로 구성되어, 가능한 모든 정답을 골라야 한다.
- 환각 식별: “주어진 문서의 내용과 다르거나 불확실한 환각 문장을 고르시오.”
- 정답 식별: “주어진 문서를 통해 파악할 수 있는 내용에 해당하는 문장을 선택하시오.”
2. 구축 방식
- 원천 데이터: AI-HUB 등록 한국어 말뭉치 및 전문 지식 데이터.
- 구축 방법: 각 도메인별 지문을 바탕으로 전문가가 사실(Fact)과 환각(Hallucination) 선택지를 직접 구성.
- 품질 관리: NIA(한국지능정보사회진흥원)의 데이터 등록 절차 및 검수 기준 준수.
- 라이선스 / 사용 조건: 한국지능정보사회진흥원(NIA) 데이터 이용 정책 준수 (AI-HUB).
3. 활용과 평가
- 주요 활용: 모델이 문맥을 근거로 허위 정보를 얼마나 정확하게 골라내는지 평가.
- 특징적인 통찰: 복수 정답 구조를 통해 모델이 일부 정보만 맞추고 넘어가는 ‘요행’을 방지하고, 전체적인 논리적 일관성을 측정함.
4. 한계 및 주의점
- 범위 한계: 한국어 및 특정 7개 도메인에 특화되어 있어 범용적인 상식 환각 평가에는 한계가 있을 수 있음.
- 해석 시 주의할 점: 정답이 리스트 형태로 제공되므로 평가 메트릭 산출 시 Precision/Recall의 적절한 조합(F1 등) 고려 필요.
Connections
- NegConstraint — 논리적 제약 조건 처리 능력 비교군
- BERTScore — 의미적 유사도 기반의 자동 평가 지표
Discussion
Comments
댓글은 승인 후 공개됩니다.