Zotero History
- Date item added to Zotero:: 2026-04-05
- First date annotations or notes modified:: 2026-04-11
- Last date annotations or notes modified:: 2026-04-11
- Export date:: 2026-04-11
DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval
Cite
Lee, T., Park, J., Hwang, S., & Jang, J. (2026). DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval (arXiv:2603.09185). arXiv. https://doi.org/10.48550/arXiv.2603.09185
TL;DR
Contribution:: Training-free negation-aware retrieval — encoder 고정 상태에서 query embedding을 contrastive loss로 직접 최적화하여 부정/제외 쿼리 처리
Pros:: 모델·모달리티 비의존적(BGE, CLIP 모두 적용), 추가 학습 데이터 불필요, CPU에서도 20 steps 0.016초로 실용적
Cons:: LLM 쿼리 분해 품질에 성능 의존(91.76% 정확도), 오디오·비디오 등 다른 modality 미검증
Study Snapshot
Key takeaway:: 부정 쿼리 문제는 fine-tuning이 아니라 inference-time embedding 최적화로 해결 가능하며, 기존 모델 위에 plug-in으로 적용 가능
Methods:: (1) LLM(GPT-4.1-nano)으로 쿼리를 positive/negative sub-query로 분해 (2) 로 query embedding 직접 최적화 (Adam, 20 steps)
Outcomes:: NegConstraint: nDCG@10 +0.0738, MAP +0.1028 (BGE-large) / COCO-Neg: Recall@5 +6% (OpenAI CLIP) / NegCLIP 위에서도 추가 향상(+2.65%)
Results:: 쿼리 분해 단독으로는 미미한 향상(RRF: MAP 0.6641), 핵심 기여는 embedding optimization(MAP 0.7379). 소형 LLM(Qwen2.5-1.5B)으로도 baseline 대비 유의미한 개선 달성
Implementations
Meta
Author:: Lee, Taegyeong
Author:: Park, Jiwon
Author:: Hwang, Seunghyun
Author:: Jang, JooYoungTitle:: DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval
Short Title::DEO Year:: 2026Citekey:: @leeDEOTrainingFreeDirect2026
itemType:: preprintDOI:: 10.48550/arXiv.2603.09185
LINK
Abstract
Recent advances in Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) have enabled diverse retrieval methods. However, existing retrieval methods often fail to accurately retrieve results for negation and exclusion queries. To address this limitation, prior approaches rely on embedding adaptation or fine-tuning, which introduce additional computational cost and deployment complexity. We propose Direct Embedding Optimization (DEO), a training-free method for negation-aware text and multimodal retrieval. DEO decomposes queries into positive and negative components and optimizes the query embedding with a contrastive objective. Without additional training data or model updates, DEO outperforms baselines on NegConstraint, with gains of +0.0738 nDCG@10 and +0.1028 MAP@100, while improving Recall@5 by +6% over OpenAI CLIP in multimodal retrieval. These results demonstrate the practicality of DEO for negation- and exclusion-aware retrieval in real-world settings.
Reading notes
🔴 Problems
Highlight (1 page, edited: [[2026-04-11]])
However, existing retrieval methods often fail to accurately retrieve results for negation and exclusion queries.
Problems:
기존 dense retrieval은 부정(negation) 및 제외(exclusion) 쿼리를 정확히 처리하지 못함
예: “2024 결과를 제외한 최신 수익 예측” 쿼리에서 embedding이 제외 의도를 반영하지 못해 원치 않는 문서가 상위 검색됨
DEO 설계의 핵심 동기
Highlight (1 page, edited: [[2026-04-11]])
To address this limitation, prior approaches rely on embedding adaptation or fine-tuning, which introduce additional computational cost and deployment complexity.
Problems:
기존 해결책(fine-tuning, embedding adaptation)의 한계:
대규모 GPU 자원, 학습 데이터셋, 과도한 훈련 비용 요구
resource-constrained 환경에서 실용성 저하
부정 쿼리 문제를 해결하려는 시도가 오히려 높은 배포 복잡도를 초래
Highlight (2 page, edited: [[2026-04-11]])
However, despite strong average performance, these models remain brittle to negation phenomena, including attribute negation (e.g., “not red”), absence (e.g., “no person”), and relational negation (e.g., “A is not left of B”).
Problems:
CLIP, BLIP 등 대형 vision-language 모델도 속성 부정(not red), 존재 부재(no person), 관계 부정(A is not left of B) 등 negation 현상에 취약 — NegBench(Alhamoud et al., 2025)로 실증됨
🟡 Prior Research
Highlight (2 page, edited: [[2026-04-11]])
Prior research has explored improvements through training strategies, distillation, and pre-training. Transfer learning on large-scale datasets such as MS MARCO (Singh et al., 2023) has also been widely adopted, though it is resourceintensive to construct
Prior Research:
Dense retrieval 기존 연구 패러다임: (1) 훈련 전략 개선 (2) 지식 증류 (3) 사전학습 (4) MSMARCO 등 대규모 데이터셋 전이학습. 공통적으로 labeled data와 상당한 GPU 자원 필요 — DEO가 회피하려는 전제조건들. zero-shot dense retrieval이 최근 등장했으나 부정 쿼리 처리는 여전히 미해결
Highlight (2 page, edited: [[2026-04-11]])
Beyond full model fine-tuning, recent work has explored methods for directly controlling or refining embedding space to improve retrieval. Representative approaches include projecting dense embeddings into interpretable sparse latent features and applying non-parametric optimization to directly adjust record embeddings for improved k-NN accuracy (Zeighami et al., 2024; Shevkunov et al.; Wang et al., 2024).
Prior Research:
Embedding 제어 선행연구:
SAE 기반(Kang et al., 2025): dense embedding을 해석 가능한 sparse latent feature로 투영하여 제어
NUDGE(Zeighami et al., 2024): 데이터 레코드 embedding을 직접 수정하는 non-parametric fine-tuning → k-NN 정확도 향상
→ 모두 대규모 데이터셋과 GPU 자원 필요 — DEO가 해결하려는 한계
Highlight (2 page, edited: [[2026-04-11]])
Prior work has attempted to address this issue through fine-tuning or task-specific regularization to improve sensitivity to negation (Wang et al., 2024; Zeighami et al., 2024), but such approaches typically incur substantial computational cost and offer limited controllability.
Prior Research:
부정 인식 retrieval 기존 접근:
Wang et al., 2024 / Zeighami et al., 2024: fine-tuning 또는 task-specific regularization으로 부정 민감도 향상 시도 → 높은 계산 비용 + 제어성 부족
NegCLIP(Yuksekgonul et al., 2022): compositional understanding을 위해 명시적 fine-tuning된 CLIP 변형
→ DEO는 NegCLIP 위에서도 추가 성능 향상을 보임 (Table 2)
🔵 Main Idea
Highlight (1 page, edited: [[2026-04-11]])
We propose Direct Embedding Optimization (DEO), a training-free method for negation-aware text and multimodal retrieval. DEO decomposes queries into positive and negative components and optimizes the query embedding with a contrastive objective.
Main Idea:
DEO의 핵심 아이디어:
쿼리를 positive/negative 컴포넌트로 분해
encoder는 고정한 채 query embedding 자체를 학습 가능한 파라미터로 취급
inference time에 contrastive loss로 직접 최적화
fine-tuning 없이 negation-aware retrieval을 실현하는 training-free 접근
Highlight (1 page, edited: [[2026-04-11]])
DEO is model- and modality-agnostic, generalizing across diverse embedding models and retrieval settings, and experiments demonstrate consistent improvements over baselines on both text and multimodal benchmarks.
Main Idea:
DEO의 범용성: 특정 embedding 모델(BGE 계열, CLIP 계열)이나 modality(text, image)에 종속되지 않음. 동일한 contrastive loss 기반 최적화 프레임워크가 text retrieval과 text-to-image retrieval 모두에서 일관된 성능 향상을 보임
🟢 Methods
Image (3 page, edited: [[2026-04-11]])
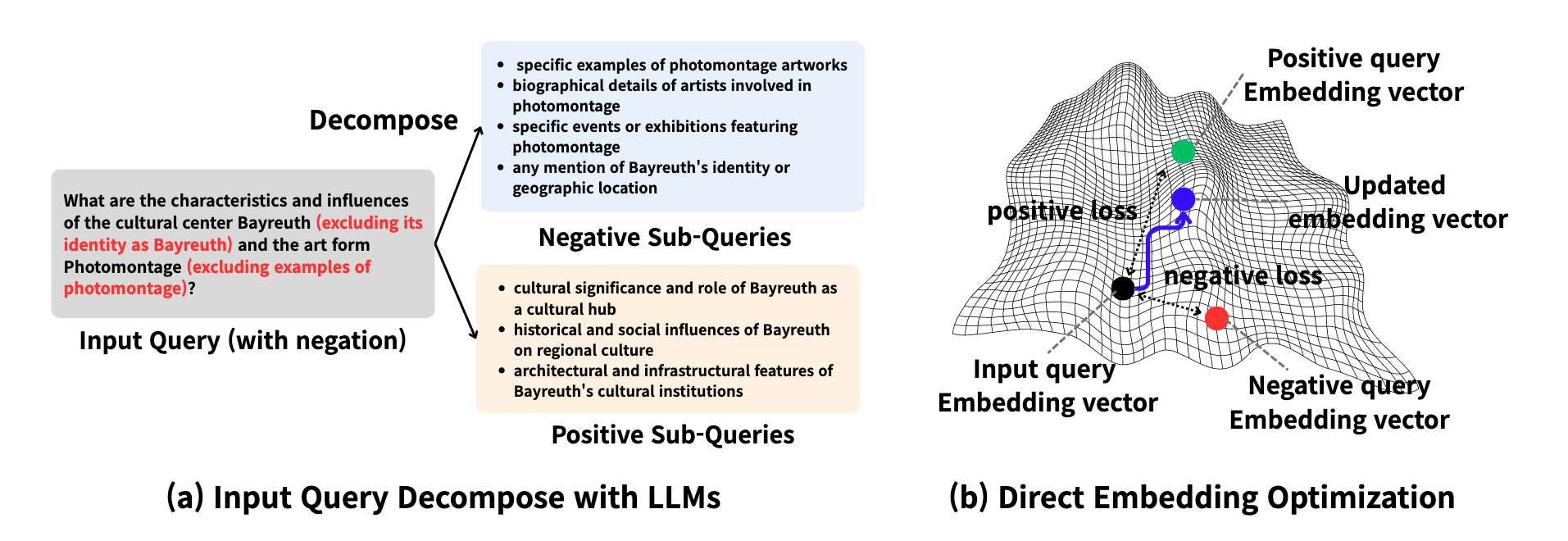
Highlight (3 page, edited: [[2026-04-11]])
our model consists of two stages: (a) Decomposing the user query into positive and negative sub-queries. (b) Directly optimizing the embedding space of input query as a parameter by using contrastive loss.
Methods:
DEO 2단계 파이프라인:
Query Decomposition: LLM이 입력 쿼리를 positive/negative sub-query로 분해
Direct Embedding Optimization: contrastive loss로 query embedding을 직접 최적화 (encoder 고정, query embedding만 학습 가능한 파라미터로 취급)
→ 추가 fine-tuning 없이 inference time에 embedding 조정
Highlight (3 page, edited: [[2026-04-11]])
we employ a large language model (LLM) in a prompt-based setting to semantically analyze the input query and explicitly capture its negation or exclusion intent. The LLM then decomposes the original query into structured positive and negative sub-queries.
Methods:
LLM 기반 쿼리 분해:
Positive sub-queries: 사용자 요청의 의미 확장된 포함 대상
Negative sub-queries: 제외 의도를 명시적으로 인코딩한 제외 대상
예: “Bayreuth(정체성 제외)의 특성과 Photomontage(예시 제외)의 영향?” → Positive 3개 / Negative 4개로 분해
GPT-4.1-nano 사용, temperature=0.1
Highlight (4 page, edited: [[2026-04-11]])
we directly optimize the embedding of the input query at inference time while keeping the encoder frozen.
Methods:
DEO Loss 함수 구성:
(i) Attraction term (): positive embedding에 가깝게 당김
(ii) Repulsion term (): negative embedding에서 밀어냄
(iii) Consistency term (): 원본 쿼리 의미 유지
Adam optimizer로 고정 step 수 최적화, encoder 파라미터는 불변
Text: , 20 steps / Multimodal:
Highlight (4 page, edited: [[2026-04-11]])
Implementation Details. We used the [CLS] token representation for all embedding models,
Methods:
구현 설정:
Embedding: [CLS] token representation 사용
검색: FAISS 라이브러리 + cosine similarity
쿼리 분해: GPT-4.1-nano (temperature=0.1)
Baseline 텍스트 모델: BGE-M3, BGE-large-en-v1.5, BGE-small-en-v1.5
Baseline 이미지 모델: OpenAI CLIP, CLIP-laion400m, CLIP-datacomp, NegCLIP
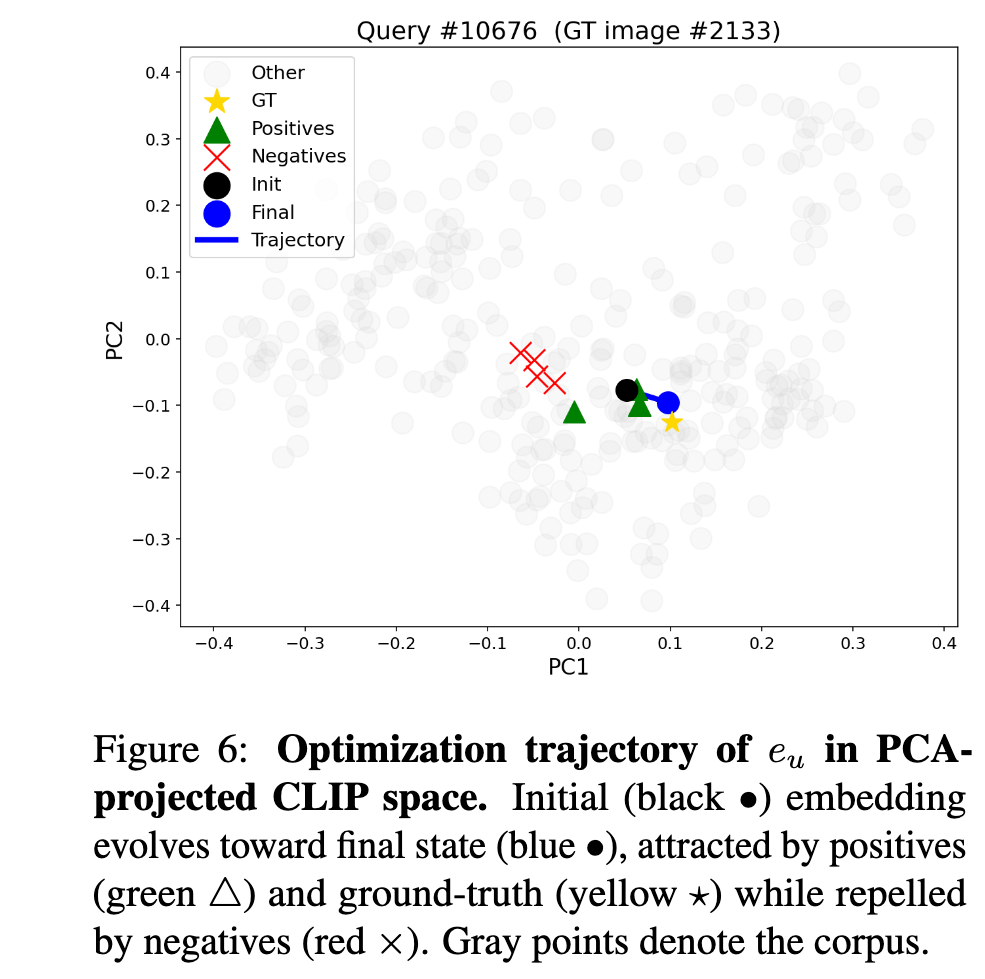
Image (8 page, edited: [[2026-04-11]])
Methods:
[Figure 6 분석] CLIP vision-language 공간에서의 embedding 궤적:
PCA 투영으로 text query embedding의 최적화 과정 시각화
초기 embedding → positive/ground-truth 방향으로 이동, negative에서 이탈
text retrieval과 동일한 궤적 패턴이 cross-modal 설정에서도 관찰됨 → DEO의 modality-agnostic 특성 실증
🟠 Limitations
Highlight (8 page, edited: [[2026-04-11]])
While DEO proves effective without fine-tuning, it relies on the ability of LLMs to correctly decompose user queries into positive and negative sub-queries. As shown in the Sec 4.3, the final retrieval performance may vary depending on the decomposition quality of the LLM.
Limitations:
DEO의 성능이 LLM의 쿼리 분해 품질에 직접 의존 — 소형 LLM(Qwen2.5-1.5B) 사용 시 대형 LLM(GPT-4.1-nano) 대비 성능 열세. 분해 정확도 91.76%이나, 나머지 8.24%의 오분해가 검색 성능에 직접 영향 → LLM 스케일에 따른 성능 편차 존재
Highlight (8 page, edited: [[2026-04-11]])
Future work could explore enhancing query decomposition with more robust LLMs, incorporating adaptive optimization strategies that automatically select loss balancing parameters per query, and extending DEO to diverse multimodal datasets beyond images, such as audio.
Limitations:
현재 DEO는 text-to-text 및 text-to-image 검색에만 검증됨. 오디오, 비디오 등 다른 modality로의 확장은 미검증 상태 — 범용 멀티모달 retrieval 시스템으로의 일반화 가능성은 미지수
🟣 Key Concepts to Clarify
Highlight (3 page, edited: [[2026-04-11]])
(a) Given an input query containing negation, we use an LLM to decompose it into positive and negative sub-queries. (b) The input query embedding is then optimized with a contrastive loss by pulling it closer to positive query embeddings and pushing it farther from negative query embeddings, enabling negation- and exclusion-aware retrieval.
Key Concepts to Clarify:
해당 논문에서 Contrastive Loss 의미: 일반적 contrastive loss는 모델 파라미터를 학습하는 데 사용되지만, DEO에서는 encoder는 완전히 고정하고 query embedding 벡터 자체를 최적화 대상(learnable parameter)으로 취급하는 것이 핵심 차별점. “Training-Free”는 모델 가중치 업데이트가 없다는 의미 — query embedding 벡터에 대한 gradient 최적화는 발생함
Highlight (4 page, edited: [[2026-04-11]])
we evaluate performance on NegConstraint using nDCG@10 and MAP@100, while NevIR is evaluated using the Pairwise metric.
Key Concepts to Clarify:
nDCG@10 (Normalized Discounted Cumulative Gain): 상위 10개 검색 결과의 관련성을 순위 가중 방식으로 측정. 상위 순위 문서에 더 높은 가중치 부여. 최대값 1.0
MAP@100 (Mean Average Precision): 상위 100개 결과에서 precision을 쿼리별 평균화
Pairwise (NevIR): 두 문서 쌍 중 부정 쿼리에 더 적합한 것을 올바르게 선택하는 비율 — 부정 변별 능력 직접 측정
Highlight (6 page, edited: [[2026-04-11]])
We introduce an Only Decompose variant that retrieves using the averaged embedding of decomposed positive and negative sub-queries, and an Only Decompose (RRF) variant that retrieves separately for each sub-query and merges results using Reciprocal Rank Fusion (RRF) with k=60.
Key Concepts to Clarify:
RRF (Reciprocal Rank Fusion): 여러 쿼리/시스템의 검색 결과 순위를 결합하는 앙상블 기법. 각 문서의 점수는 이고, 여기서 은 순위 차이를 완화하는 smoothing 파라미터. Table 6에서 RRF만으로는 DEO 대비 성능이 크게 열세(MAP: 0.6641 vs 0.7379) → embedding 최적화가 단순 결과 앙상블보다 효과적임을 시사
🟪 Results
Highlight (1 page, edited: [[2026-04-11]])
Without additional training data or model updates, DEO outperforms baselines on NegConstraint, with gains of +0.0738 nDCG@10 and +0.1028 MAP@100, while improving Recall@5 by +6% over OpenAI CLIP in multimodal retrieval.
Results:
Abstract 핵심 수치 요약:
NegConstraint: nDCG@10 +0.0738, MAP@100 +0.1028
COCO-Neg (multimodal): OpenAI CLIP 대비 Recall@5 +6%
추가 학습 데이터나 모델 업데이트 없이 달성
Image (5 page, edited: [[2026-04-11]])
Results:
[Table 1 분석] NegConstraint 벤치마크 성능:
BGE-small-en-v1.5: MAP 0.6702→0.7302 (+9.0%), nDCG@10 0.7372→0.7795 (+5.7%)
BGE-large-en-v1.5: MAP 0.6299→0.7327 (+16.3%), nDCG@10 0.7139→0.7877 (+10.3%)
BGE-M3: MAP 0.6374→0.7379 (+15.8%), nDCG@10 0.7250→0.7946 (+9.6%)
최고 성능(BGE-large-en-v1.5): MAP +0.1028, nDCG@10 +0.0738
NevIR pairwise score도 전 모델에서 일관 향상 → 부정 쿼리 변별력 개선 확인
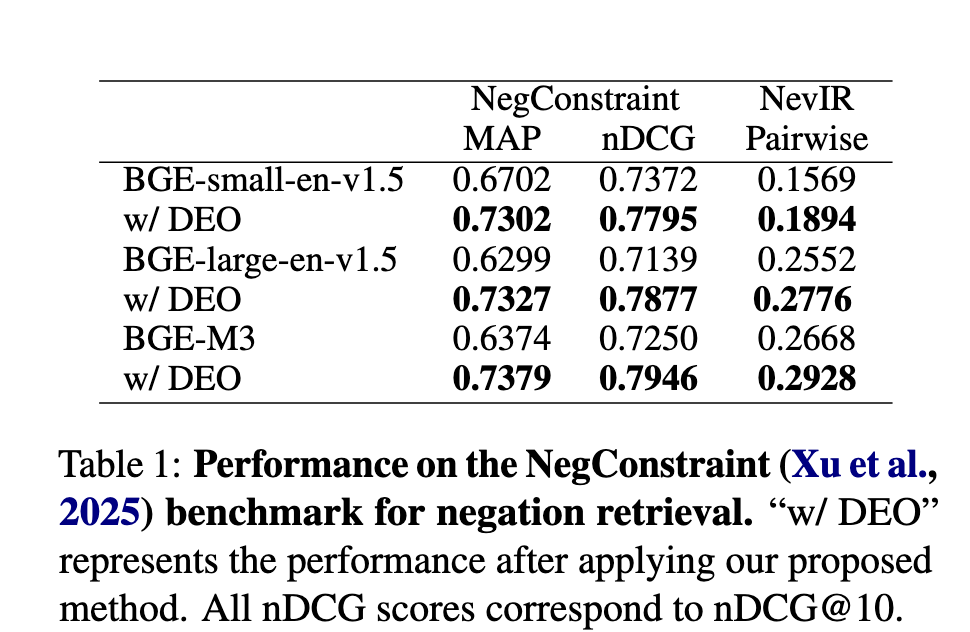
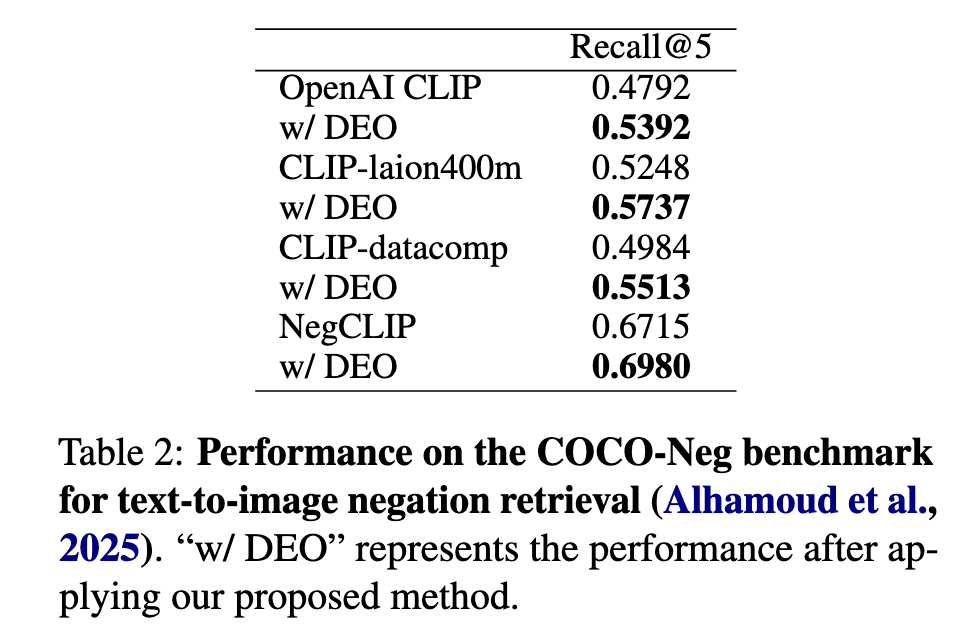
Image (5 page, edited: [[2026-04-11]])
Results:
[Table 2 분석] COCO-Neg text-to-image Recall@5:
OpenAI CLIP: 0.4792→0.5392 (+6.00%) ← 최대 향상
CLIP-laion400m: 0.5248→0.5737 (+4.89%)
CLIP-datacomp: 0.4984→0.5513 (+5.29%)
NegCLIP (fine-tuned): 0.6715→0.6980 (+2.65%)
NOTE: negation-aware 를 위해 명시적으로 fine-tuning된 NegCLIP 위에서도 추가 향상 → DEO가 fine-tuning 기반 모델과 상호 보완적
Highlight (7 page, edited: [[2026-04-11]])
To evaluate decomposition quality, we perform a binary correctness assessment on NegConstraint (Xu et al., 2025) using GPT-4.1-mini, measuring whether each output captures the intended positive and negative components of the original query. The decomposition achieves 91.76% accuracy, indicating that generated sub-queries are largely aligned with user intent.
Results:
쿼리 분해 품질 평가:
GPT-4.1-mini 기반 binary correctness 평가에서 91.76% 정확도 달성
positive/negative 컴포넌트가 원래 쿼리 의도에 대체로 부합
나머지 8.24% 오분해가 최종 검색 성능에 직접 영향 → Limitations의 LLM 의존성과 연결
Highlight (8 page, edited: [[2026-04-11]])
On a CPU (AMD Ryzen 7 5800X 8-Core Processor, 64.0GB RAM), DEO with 20 optimization steps required a total of 0.016 seconds (average 0.000665 seconds per step), while 50 steps required 0.035 seconds (average 0.000640 seconds per step). On a GPU (NVIDIA GeForce RTX 3060 12GB), DEO with 20 optimization steps required a total of 0.033 seconds (average 0.00172 seconds per step), while 50 steps required 0.095 seconds (average 0.001932 seconds per step).
Results:
계산 효율성 실측값:
CPU (AMD Ryzen 7 5800X, 64GB): 20 steps = 0.016초 (step당 0.000665초)
GPU (RTX 3060 12GB): 20 steps = 0.033초 (step당 0.00172초)
→ CPU에서도 실용적인 latency — GPU 자원이 제한된 환경에서도 real-world 배포 가능. LLM 쿼리 분해 비용이 실제 병목
🔘 Ablation Study
Image (6 page, edited: [[2026-04-11]])
Ablation Study:
[Table 5 분석] , , 조합별 성능 (BGE-M3 / OpenAI CLIP):
Text 최적: () → MAP 0.7379, nDCG@10 0.7946
Multimodal 최적: () → Recall@5 0.5392
가 text에서 최적 → 부정 의도 반영에 공격적으로 이동
이 멀티모달에서 최적 → CLIP 공유 vision-language 공간 유지에 alignment context 중요
모든 구성에서 baseline 대비 우세 → 하이퍼파라미터 변화에 강건한 설계
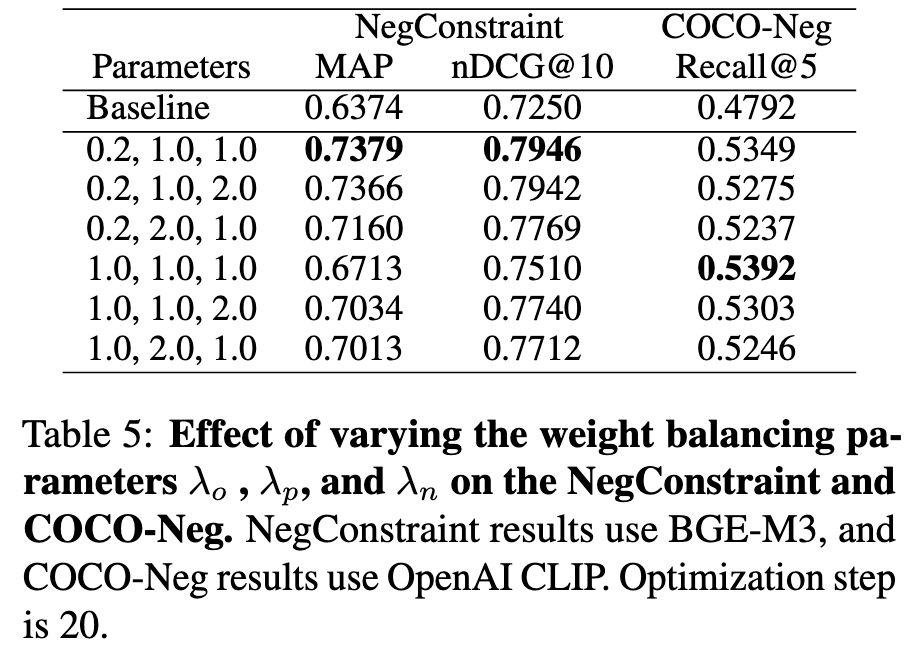
Image (6 page, edited: [[2026-04-11]])
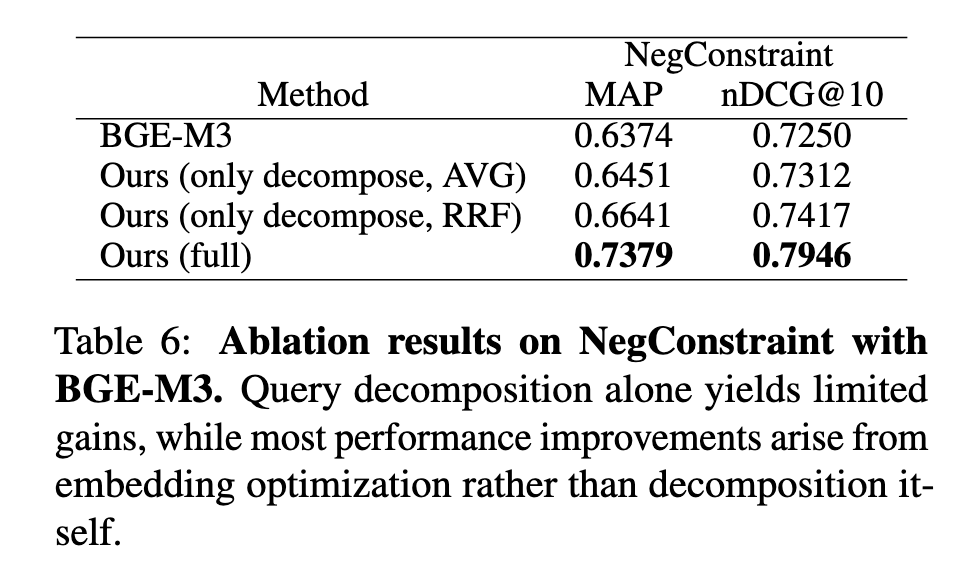
Ablation Study:
[Table 6 분석] 컴포넌트별 기여 분리 (BGE-M3, NegConstraint):
BGE-M3 baseline: MAP 0.6374, nDCG@10 0.7250
Only Decompose (AVG): MAP 0.6451, nDCG@10 0.7312 (미미한 향상)
Only Decompose (RRF): MAP 0.6641, nDCG@10 0.7417 (소폭 향상)
DEO Full: MAP 0.7379, nDCG@10 0.7946 (압도적 향상)
→ 쿼리 분해 단독으로는 성능 향상 미미. 핵심 기여는 embedding optimization 단계에서 발생. 분해는 최적화의 방향을 제공하는 보조 역할
Highlight (6 page, edited: [[2026-04-11]])
As shown in Tables 3 and 4, GPT4.1-nano consistently outperforms Qwen2.5-1.5BInstruct across all embedding models on both NegConstraint and COCO-Neg, which we attribute to more precise query decompositions from the larger model. Nevertheless, even with Qwen2.5-1.5BInstruct, our method achieves notable improvements over the baselines, indicating that DEO delivers consistent gains regardless of LLM scale.
Ablation Study:
[Table 3, 4 분석] LLM 백본에 따른 성능 비교:
NegConstraint (BGE-M3): Qwen2.5-1.5B → MAP 0.7280, nDCG@10 0.7871 / GPT-4.1-nano → MAP 0.7379, nDCG@10 0.7946
COCO-Neg: Qwen NegCLIP 0.6872 / GPT NegCLIP 0.6980
→ 대형 LLM이 쿼리 분해 정밀도가 높아 성능 우위. 그러나 소형 LLM(Qwen)도 baseline 대비 유의미한 향상 달성 → DEO의 LLM 스케일 비의존적 강건성 확인
Highlight (7 page, edited: [[2026-04-11]])
On NegConstraint (Figure 2), performance improves sharply when increasing steps from 0 to 20, and remains stable between 20 and 50 steps. However, beyond 100 steps, both nDCG@10 and MAP@100 gradually decline. On COCO-Neg (Figure 3), Recall@5 similarly improves from 0 to 20 steps, peaks around 50 steps, and slightly decreases beyond 100 steps. In both cases, 20 to 50 steps is sufficient to achieve strong performance, and we adopt 20 steps as the default setting across all experiments.
Ablation Study:
[Figure 2, 3 분석] 최적화 step 수 영향:
NegConstraint:
0→20 steps: 급격한 성능 향상
20~50 steps: 안정적 유지
100 steps 초과: nDCG@10, MAP 점진적 하락 (과최적화)
COCO-Neg:
0→20 steps: 향상, 50 steps에서 peak
100 steps 초과: 소폭 감소
→ 20 steps를 기본값으로 채택 — 성능과 효율성의 최적 균형점. 과도한 최적화는 원본 쿼리 의미( consistency term)를 훼손하는 것으로 해석
Discussion
Comments
댓글은 승인 후 공개됩니다.