Zotero History
- Date item added to Zotero:: 2026-03-23
- First date annotations or notes modified:: 2026-03-23
- Last date annotations or notes modified:: 2026-03-27
- Export date:: 2026-03-27
Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction
Cite
Fang, Y., Chen, B., Peng, J., Li, X., Xi, Y., Zhang, C., & Zhong, G. (2025). Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction (arXiv:2505.24347). arXiv. https://doi.org/10.48550/arXiv.2505.24347
TL;DR
Contribution:: fine-tuning/외부 정보 없이 범용 LLM만으로 동작하는 3단계 hallucination 억제 ASR 교정 프레임워크 (Pre-Detection + CoT Subtask + Verification)
Pros:: 추가 학습/데이터 불필요, 중국어·영어 모두 적용 가능, 각 단계가 modular하게 hallucination 억제에 기여
Cons:: del/ins 오류 소폭 증가(hallucination 완전 제거 불가), CoT 도입 시 토큰 비용 급증(~4배), 복수 오류 문장의 정량화 어려움
Study Snapshot
Key takeaway:: plain prompt LLM 적용 시 CER 변화량이 baseline 대비 949% 증가(5.06→53.10)하지만, 3단계 프레임워크 적용 시 baseline 대비 최대 21% 개선.
Methods:: Conformer-based AED ASR + GPT-4o/DeepSeek-V2, AISHELL-1/2 + LibriSpeech 벤치마크
Outcomes:: substitution 오류 교정 효과적, Noun Recall 향상, chunk 기반 디코딩 설정에서도 유효.
Results:: AISHELL-1 21%, AISHELL-2 11%, LibriSpeech test-clean 9%, test-other 11.4% CER/WER 상대적 감소
Implementations
Meta
Author:: Fang, Yangui
Author:: Chen, Baixu
Author:: Peng, Jing
Author:: Li, Xu
Author:: Xi, Yu
Author:: Zhang, Chengwei
Author:: Zhong, GuohuiTitle:: Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction
Short Title::Fewer Hallucinations, More Verification Year:: 2025Citekey:: @fangFewerHallucinationsMore2025
itemType:: preprintDOI:: 10.48550/arXiv.2505.24347
LINK
Abstract
Automatic Speech Recognition (ASR) error correction aims to correct recognition errors while preserving accurate text. Although traditional approaches demonstrate moderate effectiveness, LLMs offer a paradigm that eliminates the need for training and labeled data. However, directly using LLMs will encounter hallucinations problem, which may lead to the modification of the correct text. To address this problem, we propose the Reliable LLM Correction Framework (RLLM-CF), which consists of three stages: (1) error pre-detection, (2) chain-of-thought sub-tasks iterative correction, and (3) reasoning process verification. The advantage of our method is that it does not require additional information or fine-tuning of the model, and ensures the correctness of the LLM correction under multi-pass programming. Experiments on AISHELL-1, AISHELL-2, and Librispeech show that the GPT-4o model enhanced by our framework achieves 21%, 11%, 9%, and 11.4% relative reductions in CER/WER.
Reading notes
🔴 Problems
Highlight (1 page, edited: [[2026-03-27]])
Although traditional approaches demonstrate moderate effectiveness, LLMs offer a paradigm that eliminates the need for training and labeled data. However, directly using LLMs will encounter hallucinations problem, which may lead to the modification of the correct text.
Problems:
LLM을 ASR 교정에 직접 적용하면 hallucination으로 인해 올바른 텍스트까지 잘못 수정하는 역효과 발생 → RLLM-CF 설계의 핵심 동기
Highlight (1 page, edited: [[2026-03-27]])
However, these methods typically require either domain-specific fine-tuning or additional contextual information, which constrains their scalability in real-world applications. Therefore, leveraging the general knowledge embedded in LLMs without fine-tuning or external inputs emerges as a more practical and scalable alternative. Nevertheless, directly applying general LLMs often results in hallucination issues [20], posing a significant challenge to reliable correction.
Problems:
기존 방법들은 domain fine-tuning 또는 외부 정보(N-best list 등) 필요 → 확장성 제한.
일반 LLM을 직접 적용하면 hallucination이 발생하여 reliable correction을 저해함.
Highlight (2 page, edited: [[2026-03-27]])
Hallucinations in LLMs refer to instances where the generated responses, while grammatically correct, fluent, and plausible, deviate from the input or contradict factual information [21], [22]. In the context of ASR error correction, model-induced hallucinations are closely linked to transcription errors.
Problems:
LLM hallucination 정의 — 문법적으로 유창하고 그럴듯하나 입력과 다르거나 사실과 모순되는 응답. ASR 교정 맥락에서 원본 오디오에 없는 내용을 fabrication → 전사 오류와 직결
Image (3 page, edited: [[2026-03-27]])
Problems:
[Table I 분석] LLM hallucination 유형별 상세:
[Faithful Hallucinations]
Instruction Violation: 교정 대신 질문 거부 응답 (“Sorry, I can’t answer”)
Redundant Output: 교정 결과에 불필요한 텍스트 추가 (“This answer is: …“)
Continue Writing: 원문을 임의로 이어써서 확장
Blank Output: 아무것도 출력하지 않음
Repeated Output: 단어를 무한 반복 출력
Grammar Correction: ASR 오류가 아닌 문법 자체를 과교정 (올바른 텍스트를 잘못 수정하는 핵심 문제)
[Factual Hallucinations]
- Make Mistake: 오류 단어를 다른 오류 단어로 대체 (hask→task가 아닌 다른 단어로)
→ 논문 주장 연결: Pre-Detection이 Faithful을, Verification이 두 유형 모두를 차단하는 설계 근거
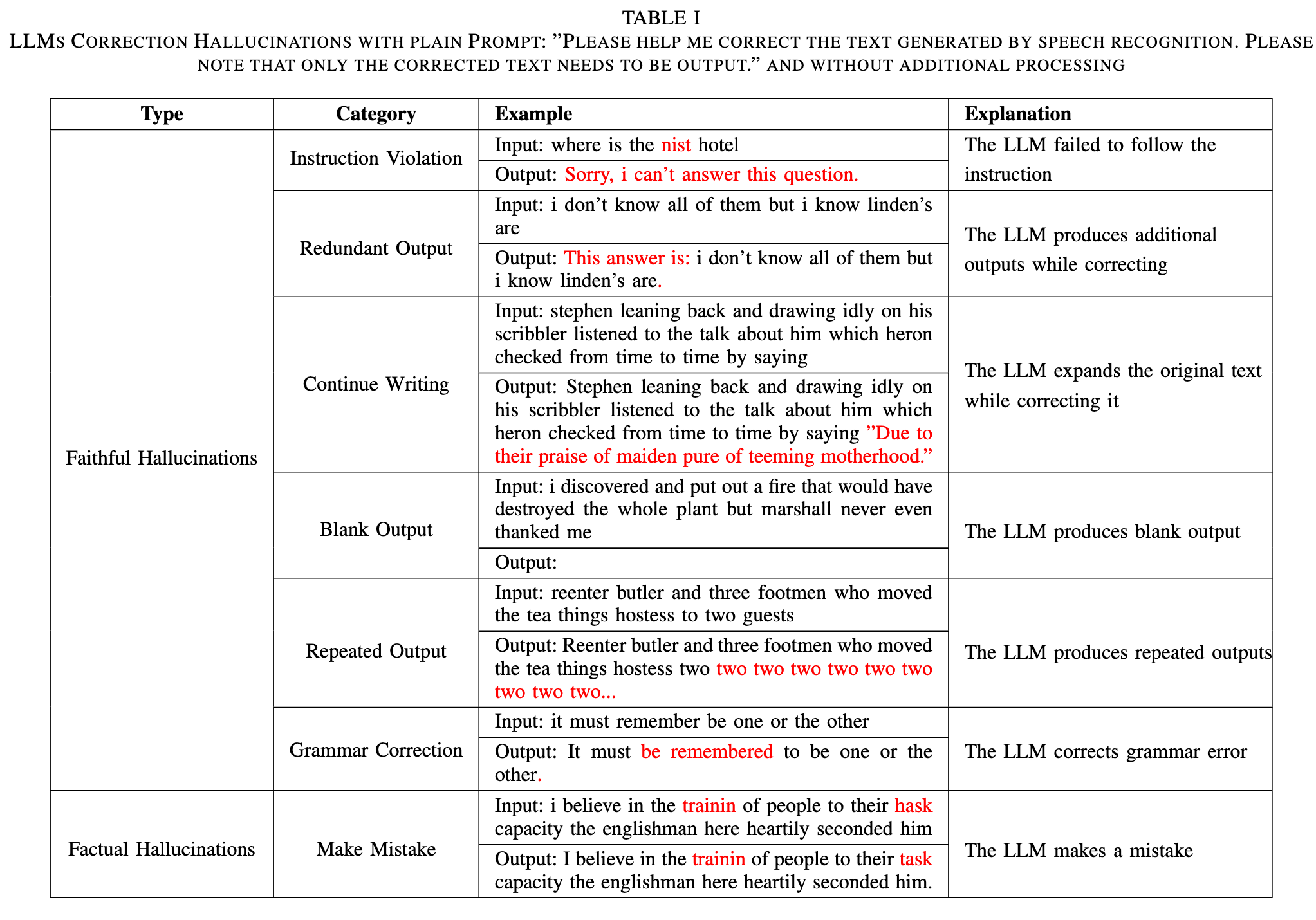
Highlight (4 page, edited: [[2026-03-27]])
we categorize LLM hallucinations in ASR error correction into two types: faithful hallucinations—including instruction violations, redundant outputs, continuation of writing, blank outputs, and grammar corrections—and factual hallucinations, characterized by content errors.
Problems:
Table I 근거 텍스트: hallucination을 Faithful(명령위반/중복출력/이어쓰기/빈출력/반복출력/문법과교정)과 Factual(내용오류) 두 유형으로 분류. 이 분류가 RLLM-CF 3단계 설계 근거 — Pre-Detection은 Faithful을, Verification은 두 유형 모두 억제
🟡 Prior Research
Highlight (1 page, edited: [[2026-03-27]])
Autoregressive models exploit encoder-decoder architectures with Connectionist Temporal Classification (CTC) loss [10], including translation-style correction frameworks [7], [8] and entity-aware transformers [9]. In parallel, non-autoregressive edit-based models such as FastCorrect [1], [2] and SoftCorrect [4] predict edit operations through duration modeling and integrate CTC loss with sequence-to-sequence frameworks to enhance error detection.
Prior Research:
기존 ASR 교정 두 가지 패러다임 — (1) autoregressive seq2seq (CTC loss, translation-style, entity-aware transformer) (2) non-autoregressive edit 기반 (FastCorrect, SoftCorrect). 모두 대규모 labeled data와 task-specific training 의존
Highlight (2 page, edited: [[2026-03-27]])
In recent years, integrating LLMs into ASR error correction pipelines has attracted increasing attention. Min and Wang [20] investigated the direct application of LLMs for error correction and concluded that models such as GPT-4o are ineffective due to hallucination issues. Ma et al. [19] explored combining Nbest rescoring with LLM-based correction; however, obtaining the N-best list from the ASR system may impose additional costs in practice. Yang et al. [18] compared LLM-based rescoring and generation methods, demonstrating that the latter outperforms the former when domain-specific information is provided or the LLM is fine-tuned. Nevertheless, such approaches require either domain knowledge or fine-tuning.
Prior Research:
Min & Wang [20] — GPT-4o도 hallucination으로 직접 교정에 비효과적. Ma et al. [19] — N-best rescoring + LLM 결합, 그러나 N-best 획득 추가 비용. Yang et al. [18] — 도메인 정보/fine-tuning 시 generation > rescoring이나 외부 자원 의존. 모두 supplementary resource 또는 fine-tuning 필요
🔵 Main Idea
Highlight (1 page, edited: [[2026-03-27]])
we propose the Reliable LLM Correction Framework (RLLMCF), which consists of three stages: (1) error pre-detection, (2) chain-of-thought sub-tasks iterative correction, and (3) reasoning process verification. The advantage of our method is that it does not require additional information or fine-tuning of the model, and ensures the correctness of the LLM correction under multipass programming.
Main Idea:
RLLM-CF 3단계 프레임워크 — (1) Error Pre-Detection (2) CoT Subtask Iterative Correction (3) Reasoning Process Verification. fine-tuning 및 외부 정보 없이 LLM 사전학습 지식만으로 hallucination 억제
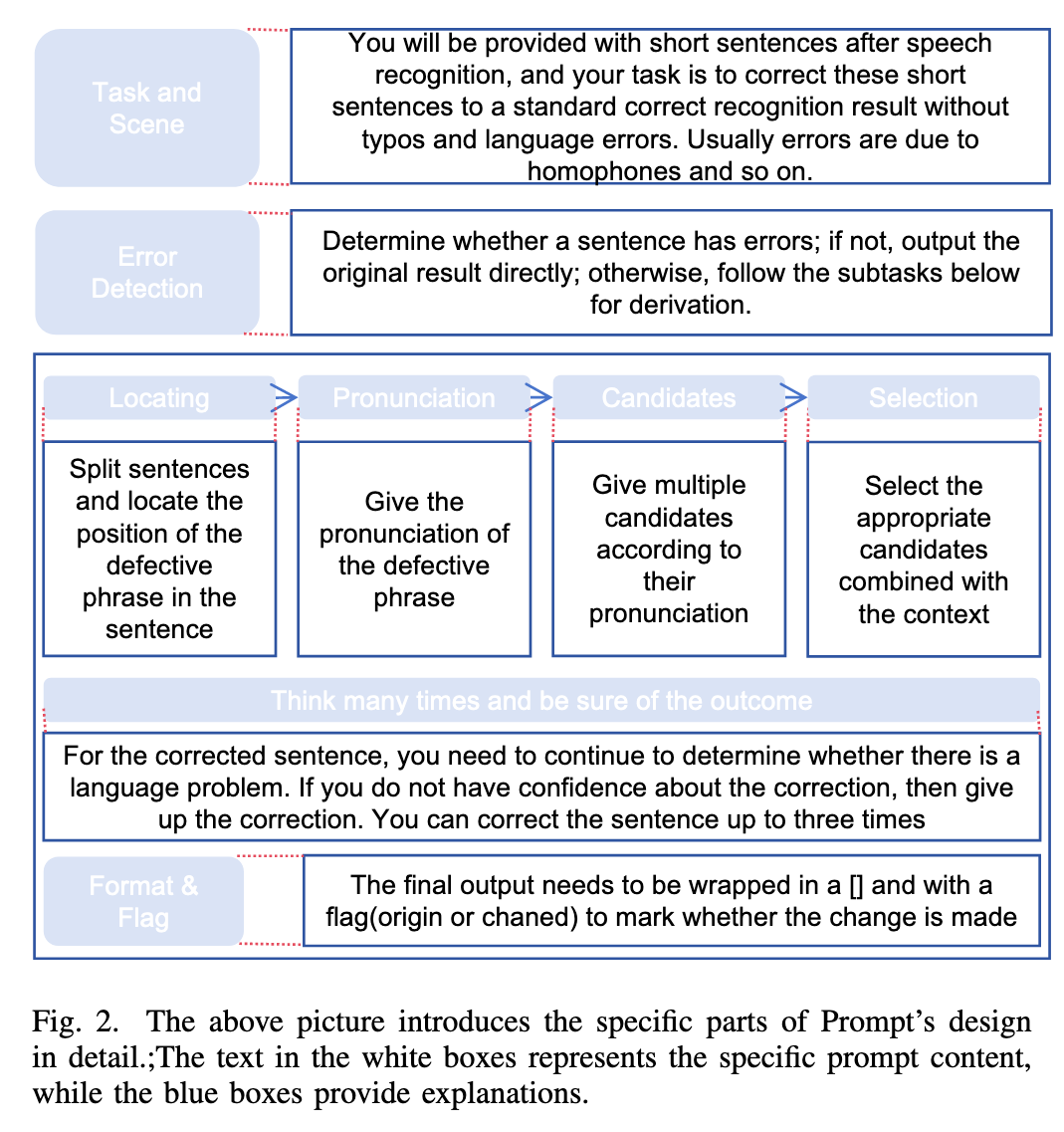
Image (3 page, edited: [[2026-03-27]])
Main Idea:
Prompt 설계 구조 (Figure 2): Task/Scene → Error Detection → 4개 Sub-Tasks (Locating / Pronunciation / Candidates / Selection) → Format & Flag 의 계층적 구조. “Think many times and be sure of the outcome” 문구가 iterative correction의 prompt 수준 유도 장치. few-shot 3개 예시 포함으로 LLM 출력 공간을 구조화
🟢 Methods
Image (2 page, edited: [[2026-03-26]])
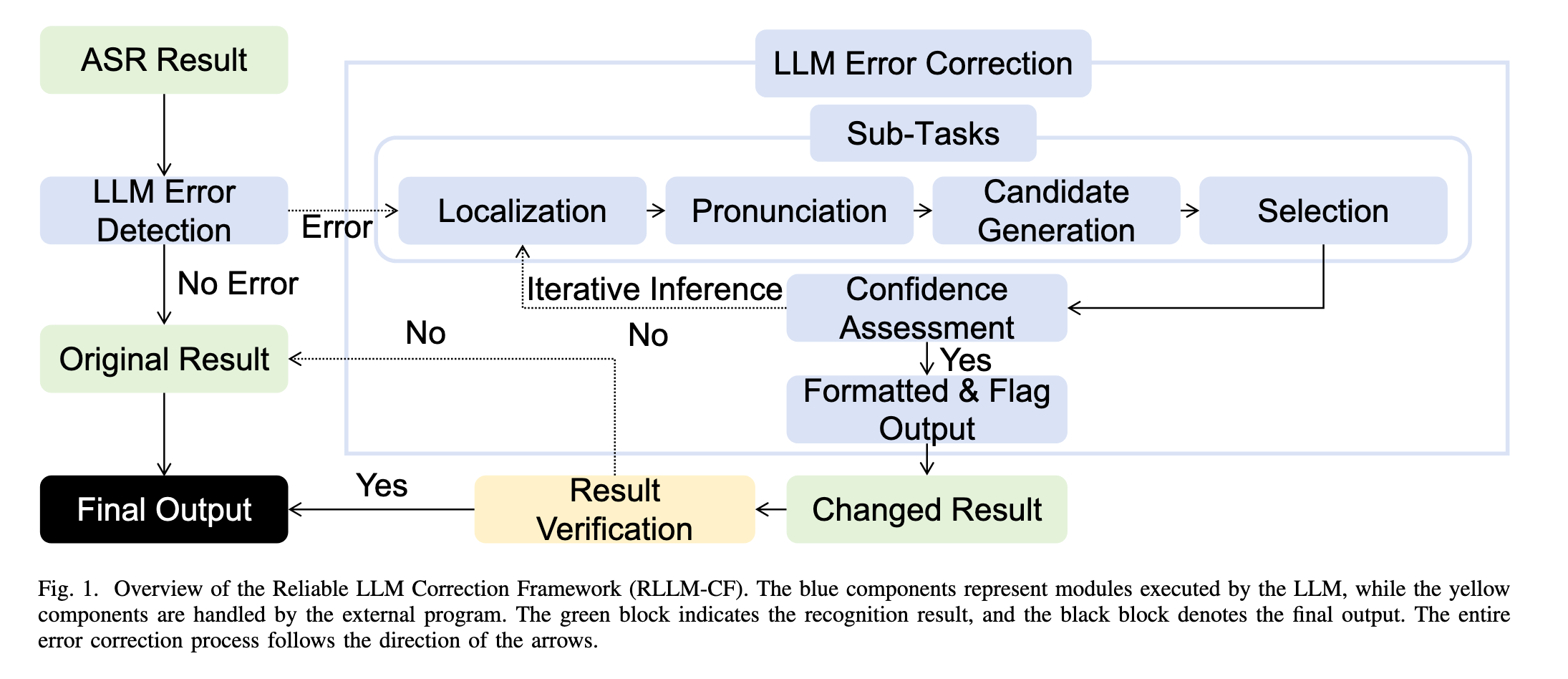
Highlight (3 page, edited: [[2026-03-27]])
This highlights the necessity of adopting an error prevention first strategy for correction tasks. To prevent LLMs from altering correct content, we first instruct the model to detect errors in the input sentence. If no errors are detected, the sentence is directly retained; otherwise, the model proceeds to the correction stage, referred to as Stage 1 in Algorithm 1.
Methods:
Stage 1 (Error Pre-Detection): 오류 감지 후 오류 없으면 원문 그대로 반환 → LLM이 올바른 텍스트를 수정하는 것을 원천 차단. “error prevention first” 전략의 핵심
Highlight (3 page, edited: [[2026-03-27]])
To address this, we decompose the correction task into four subtasks—localization, pronunciation assessment, candidate generation, and candidate selection—following a CoT strategy to improve reasoning reliability, as illustrated in Figure 3.
Methods:
Stage 2 (CoT Subtask Iterative Correction): 교정을 4개 서브태스크로 분해 — (1)localization (2)pronunciation assessment (3)candidate generation (4)candidate selection. 신뢰도 낮으면 최대 3회 반복 교정
Highlight (3 page, edited: [[2026-03-27]])
Following the correction, a verification step is conducted to ensure compliance with task instructions. Specifically, we employ the model’s output to assess: (1) whether the answer conforms to the required format, and (2) whether all reasoning steps are correctly completed. Only when both criteria are sat
Methods:
Stage 3 (Answer Verification): (1) 요구 형식 준수 여부 (2) 모든 추론 단계 완료 여부 — 두 조건 모두 충족 시에만 교정 결과 채택, 미충족 시 원문 반환
Image (3 page, edited: [[2026-03-27]])
Methods:
Figure 3 CoT 실제 예시 분석: “bread” → “breed” 교정 과정. (1) Locate: “bread” 위치 특정 (2) Pronunciation: /bred/ 발음 확인 (3) Candidates: “breed”/briːd/, “bled”/blɛd/, “brand”/brænd/ 생성 (4) Selection: 문맥(“bakers”) 고려해 “breed” 선택. 발음 유사성 + 문맥 결합이 핵심 — 순수 언어모델 지식으로 동음이의어 ASR 오류를 교정하는 방식 실증

Highlight (4 page, edited: [[2026-03-27]])
In our experiment, we adopt a conformer-based attentionencoder-decoder (AED) ASR model trained with the WeNet toolkit [28], following the U2++ [29] method, across three datasets. For AISHELL-1 and LibriSpeech, a non-streaming model architecture is employed, and four decoding strategies are evaluated: Attention, Attention Rescoring, CTC Greedy Search, and CTC Prefix Search. To further assess the performance of streaming models, experiments are conducted on AISHELL-2 using the Attention Rescoring decoding method with a chunk size of 16. The Conformer encoder comprises 12 blocks with an attention dimension of 256, 4 attention heads, and 2048 linear units, incorporating relative positional encoding and Swish activation. The decoder is implemented as a bidirectional Transformer with three forward and three backward layers. The network follows a hybrid CTC/attention architecture, with the CTC loss weight set to 0.3.
Methods:
ASR 모델 구성 상세: Conformer encoder (12 blocks, dim 256, 4 heads, 2048 FFN, relative positional encoding, Swish activation) + Bidirectional Transformer decoder (3 forward + 3 backward layers). Hybrid CTC/Attention, CTC loss weight 0.3. AISHELL-2는 chunk size 16 streaming 모델. WeNet toolkit + U2++ 방법 → 4가지 decoding 전략(Attention / Attention Rescore / CTC Greedy / CTC Prefix) 모두 지원
🟠 Limitations
Highlight (5 page, edited: [[2026-03-27]])
Experiments with DeepSeek-V2 on LibriSpeech yielded suboptimal performance, as DeepSeek-V2 is primarily designed for Chinese and demonstrates limited capability on English datasets.
Limitations:
DeepSeek-V2 영어 성능 저조: DeepSeek-V2는 중국어 특화 설계로 LibriSpeech(영어)에서 suboptimal 성능. 반면 GPT-4o는 중·영 모두 강점 → RLLM-CF 성능이 backbone LLM 품질에 크게 의존. 범용성 주장(no fine-tuning, cross-domain)과 상충: 실제론 강력한 다국어 LLM이 전제조건
Highlight (5 page, edited: [[2026-03-27]])
However, a slight increase in deletion and insertion errors is observed, primarily due to hallucinations.
Limitations:
교정 후 deletion/insertion 오류 소폭 증가 → hallucination 완전 제거 불가. substitution 교정에는 효과적이나 구조적 오류(삽입/삭제) 억제에 한계
Highlight (6 page, edited: [[2026-03-27]])
For sentences containing multiple errors, the overall error count was reduced, although precise quantification remains challenging.
Limitations:
복수 오류 포함 문장에서 오류 감소량 정밀 정량화 어려움. 실제로 98개의 원래 올바른 문장이 잘못 교정됨(383개 교정 성공 대비) → hallucination 완전 제거 불가 한계 재확인
🟣 Key Concepts to Clarify
Highlight (1 page, edited: [[2026-03-27]])
Connectionist Temporal Classification (CTC) loss
Key Concepts to Clarify:
CTC (Connectionist Temporal Classification): 입력·출력 길이가 달라도 학습 가능한 시퀀스 레이블링 loss. ASR에서 음성 프레임↔텍스트 토큰 정렬 문제를 해결. CTC Greedy / Prefix Search는 이 출력을 디코딩하는 전략 → Table II~III의 4가지 decoding 행 구성 근거
Highlight (1 page, edited: [[2026-03-27]])
Chain-of-Thought (CoT) prompting to enhance reasoning [15].
Key Concepts to Clarify:
Chain-of-Thought (CoT) Prompting: LLM이 최종 답만 바로 출력하는 대신 중간 추론 단계를 명시적으로 생성하도록 유도하는 prompting 기법 [Wei et al., 2022]. 복잡한 추론 신뢰도 향상 → RLLM-CF Stage 2의 이론적 근거. 단순 CoT만으로는 부족해서 iterative correction을 추가한 것이 핵심 기여
Highlight (1 page, edited: [[2026-03-27]])
Fine-tuning approaches, often using low-rank adaptation (LoRA)
Key Concepts to Clarify:
LoRA (Low-Rank Adaptation): 대형 모델의 전체 파라미터를 재학습하지 않고 저차원 행렬 분해를 통해 소수 파라미터만 fine-tuning하는 경량 기법. 본 논문은 LoRA조차 사용하지 않음 → “no fine-tuning” 주장의 의미: LoRA 포함 어떠한 파라미터 업데이트도 없이 순수 prompting만 사용
Highlight (2 page, edited: [[2026-03-27]])
however, obtaining the N-best list from the ASR system may impose additional costs in practice.
Key Concepts to Clarify:
N-best list: ASR 디코더가 최상위 1개 결과만 반환하는 대신, 확률 높은 상위 N개 후보 시퀀스를 반환하는 방식. LLM이 이 N개 후보 중 가장 적합한 것을 재선택(rescoring)하는 데 활용. 하지만 N-best list 생성 자체가 추가 연산 비용 → 본 논문이 이를 사용하지 않는 이유
Highlight (5 page, edited: [[2026-03-27]])
To analyze noun recall within substitution errors, noun filtering was performed using the method proposed in [32] for Chinese (AISHELL-1/2) and [33] for English (LibriSpeech).
Key Concepts to Clarify:
Noun Recall: 교정 후 고유명사/전문용어가 얼마나 잘 복원됐는지 측정하는 지표. ASR 오류가 동음이의어 기반으로 특히 고유명사에서 빈번하므로 별도 측정. 중국어는 N-LTP [32], 영어는 NLTK [33]로 명사 필터링. CER/WER 개선과 함께 Noun Recall 향상이 LLM 교정의 핵심 강점 — 문맥 이해 기반 동음이의어 분별 능력
🟪 Results
Highlight (1 page, edited: [[2026-03-27]])
Experiments on AISHELL-1, AISHELL-2, and Librispeech show that the GPT-4o model enhanced by our framework achieves 21%, 11%, 9%, and 11.4% relative reductions in CER/WER.
Result:
GPT-4o + RLLM-CF 최종 성능 — AISHELL-1: 21%, AISHELL-2: 11%, LibriSpeech test-clean: 9%, test-other: 11.4% CER/WER 상대적 감소. 상세 수치는 Table II~IV 참조
Image (5 page, edited: [[2026-03-27]])
Results:
[Table II 분석] AISHELL-1 CER / Noun Recall (GPT-4o vs DeepSeek-V2):
[GPT-4o]
Attention: 5.06→4.32 (-14.6%), Attention Rescore: 4.62→4.01 (-13%)
CTC Greedy/Prefix: 5.17→4.06 (-21%) ← Abstract 21% 수치 출처
평균 17.4% 상대 감소, Noun Recall +2~3pp 향상
[DeepSeek-V2]
최고 CTC Prefix: 5.17→4.48 (-13%)
GPT-4o 대비 전반적으로 열세
[논문 주장 연결]
sub 오류 크게 감소, del/ins 소폭 증가 → hallucination 완전 제거 불가, Limitations와 일치
GPT-4o > DeepSeek-V2 일관 우세 → 모델 품질이 교정 성능에 직결
Noun Recall 향상 → LLM이 동음이의어 기반 고유명사 오류 교정에 효과적
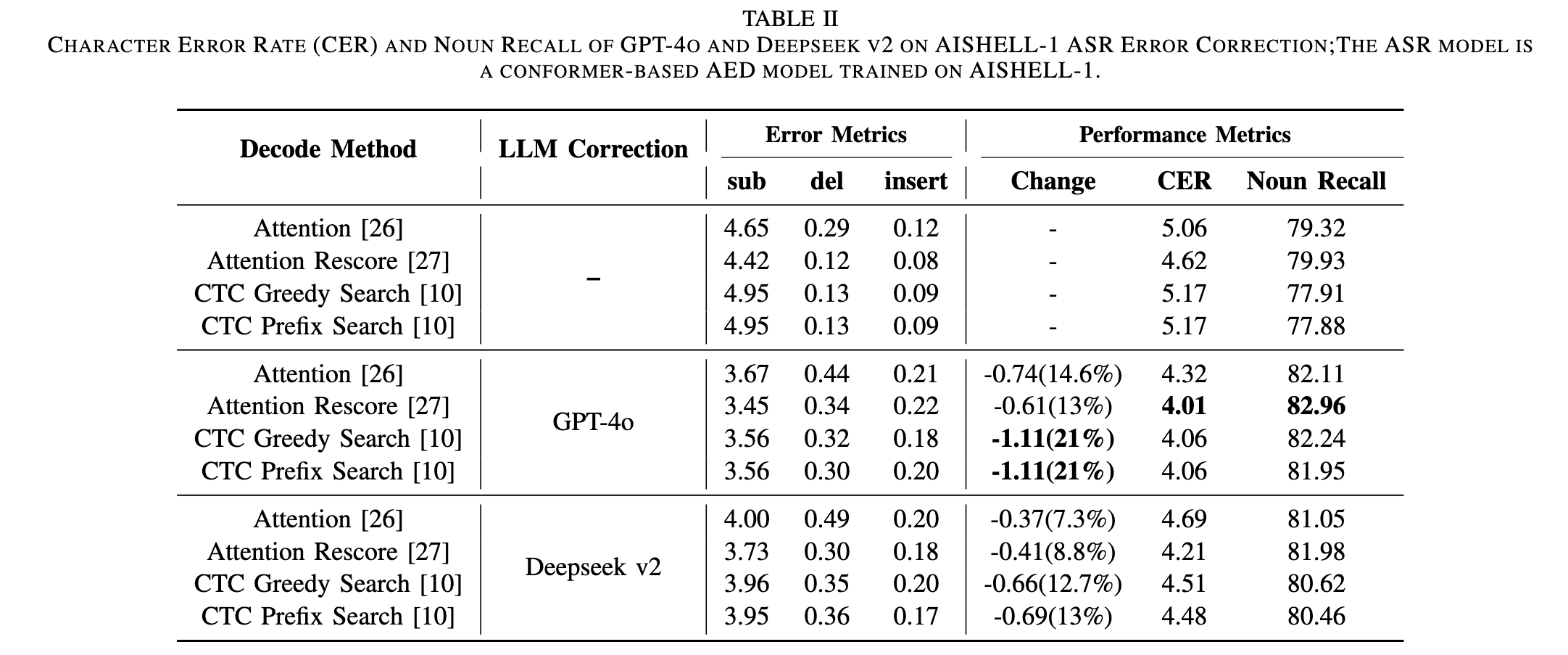
Image (5 page, edited: [[2026-03-27]])
Results:
[Table III 분석] LibriSpeech WER (GPT-4o, test-clean/other):
[test-clean]
Attention Rescore: 3.35→3.19 (-4.8%, 최저 WER)
평균 5.72% 상대 감소 / 최대 9%: CTC Greedy 3.77→3.43 (-0.34pp) ← Abstract 9% 수치 출처
[test-other (잡음 환경)]
CTC Greedy: 9.52→8.45 (-11.2%, -1.07pp); 최대 11.4%는 CTC Prefix 9.50→8.41 (-1.09pp) ← Abstract 11.4% 수치 출처
절대 감소폭이 test-clean보다 큼 → 오류 많을수록 교정 효과 증가
[논문 주장 연결]
영어에서도 유효 → fine-tuning 없이 언어 범용성 확보 주장 지지
AISHELL-1의 21% 대비 낮음 → LLM의 중국어 동음이의어 패턴 인식이 더 강함
del/ins 증가 패턴 동일 → hallucination 언어 무관하게 잔존
[Table IV 분석] AISHELL-2 Streaming CER:
GPT-4o: 5.57→4.95 (-11%) ← Abstract 11% 수치 출처
Streaming 모델에서도 RLLM-CF 유효성 확인
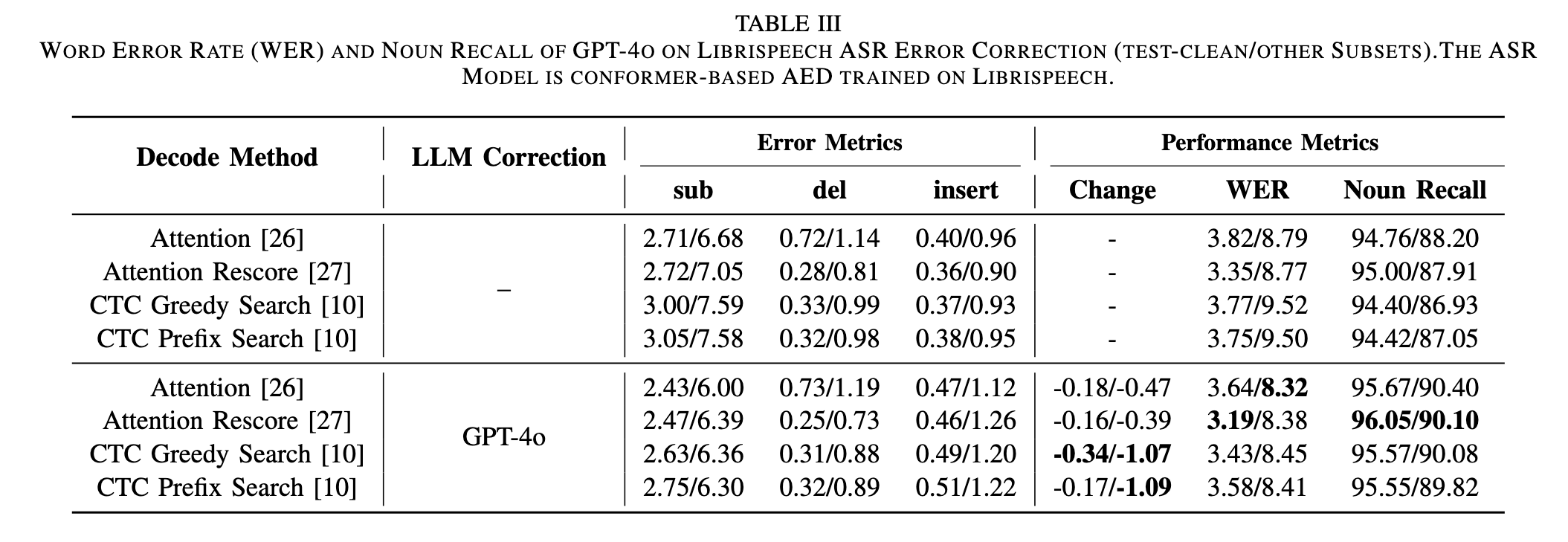
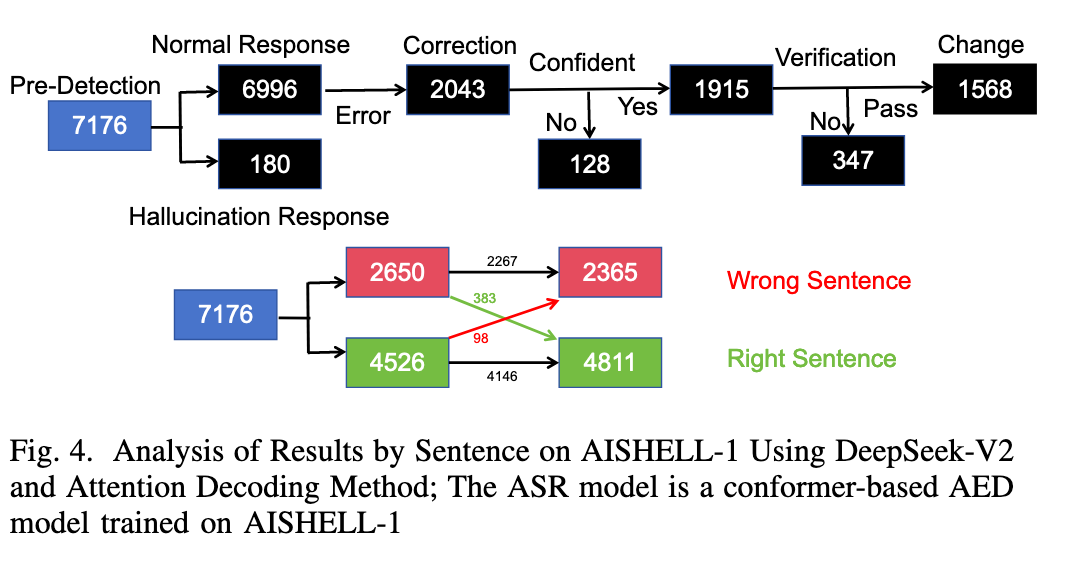
Image (5 page, edited: [[2026-03-27]])
Results:
[Figure 4 분석] 7,176 문장 sentence-level 흐름: Pre-Detection에서 2,043개 오류 감지 → 이 중 1,915개 confidence 확보, 128개 반복 후 포기 → Verification에서 347개 추가 탈락 → 최종 1,568개 교정 시도 → 383개 성공 교정 / 98개 오정정(원래 맞는 문장을 틀리게). 정밀도 관점: 383/(383+98) = 약 79.6% → hallucination 완전 제거 불가 한계 수치화
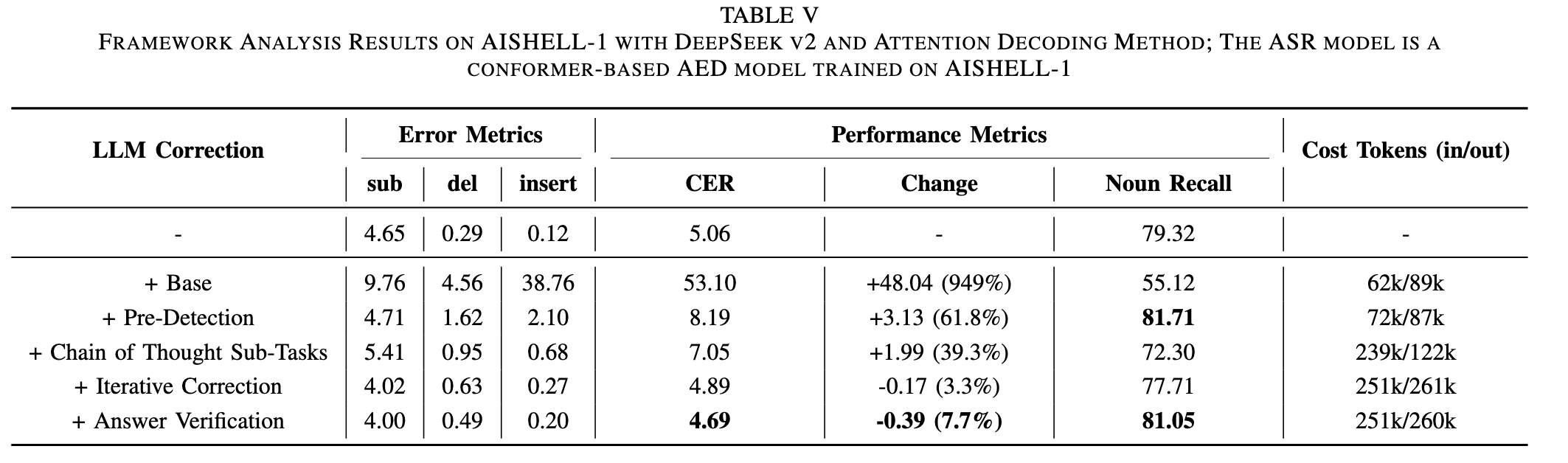
🔘 Ablation Study
Image (5 page, edited: [[2026-03-27]])
Ablation Study:
[Table V 분석] 컴포넌트별 CER 변화 (AISHELL-1, DeepSeek-V2, Attention Decoding):
[단계별 CER]
Baseline: 5.06 (교정 없음)
+Base (plain prompt): 53.10 (+949%) → hallucination 폭발, 사용 불가 수준
+Pre-Detection: 8.19 → 가장 큰 단일 개선, Faithful hallucination 억제
+CoT Sub-Tasks: 7.05 → insertion/deletion 억제, LLM 출력 공간 제한
+Iterative Correction: 4.89 → baseline 이하 첫 진입, 단일 패스 한계 극복
+Answer Verification: 4.69 → 최종 hallucination 잔존 제거
[Token 비용]
- Base: 62k/89k → CoT: 239k/122k (입력 급증) → Iterative+Verification: 251k/260k 안정
[논문 주장 연결]
Pre-Detection이 핵심 기여 단계 → “error prevention first” 전략 유효성 실증
CoT 단독으로는 baseline 이하 달성 불가 → Iterative가 필수 보완재
Verification 추가는 거의 무비용(토큰 증가 없음) 대비 효과 → 효율적 설계
각 컴포넌트 순차적 상호보완 → 3단계 전체 필요성 정당화
[Table V 분석] 토큰 소비 분석:
Base: 62k/89k → +Pre-Detection: 72k/87k (입력 소폭 증가) → +CoT Sub-Tasks: 239k/122k (입력 급증, 출력 감소) → +Iterative+Verification: 251k/260k (출력 급증).
CoT가 입력 토큰을 3배 이상 증가시키는 주요 비용 원인.
Verification은 토큰 추가 비용 거의 없이 성능 향상 → 가장 효율적인 컴포넌트. 실험 시 여러 문장을 묶어서 inference → 토큰 비용 절감
Discussion
Comments
댓글은 승인 후 공개됩니다.