TL;DR
스레드는 하나의 프로세스 안에서 실행되는 실행 흐름이다. 운영체제 수준 스레드는 같은 프로세스의 주소 공간을 공유하되, 각자 stack과 실행 상태를 가진다.
스레드
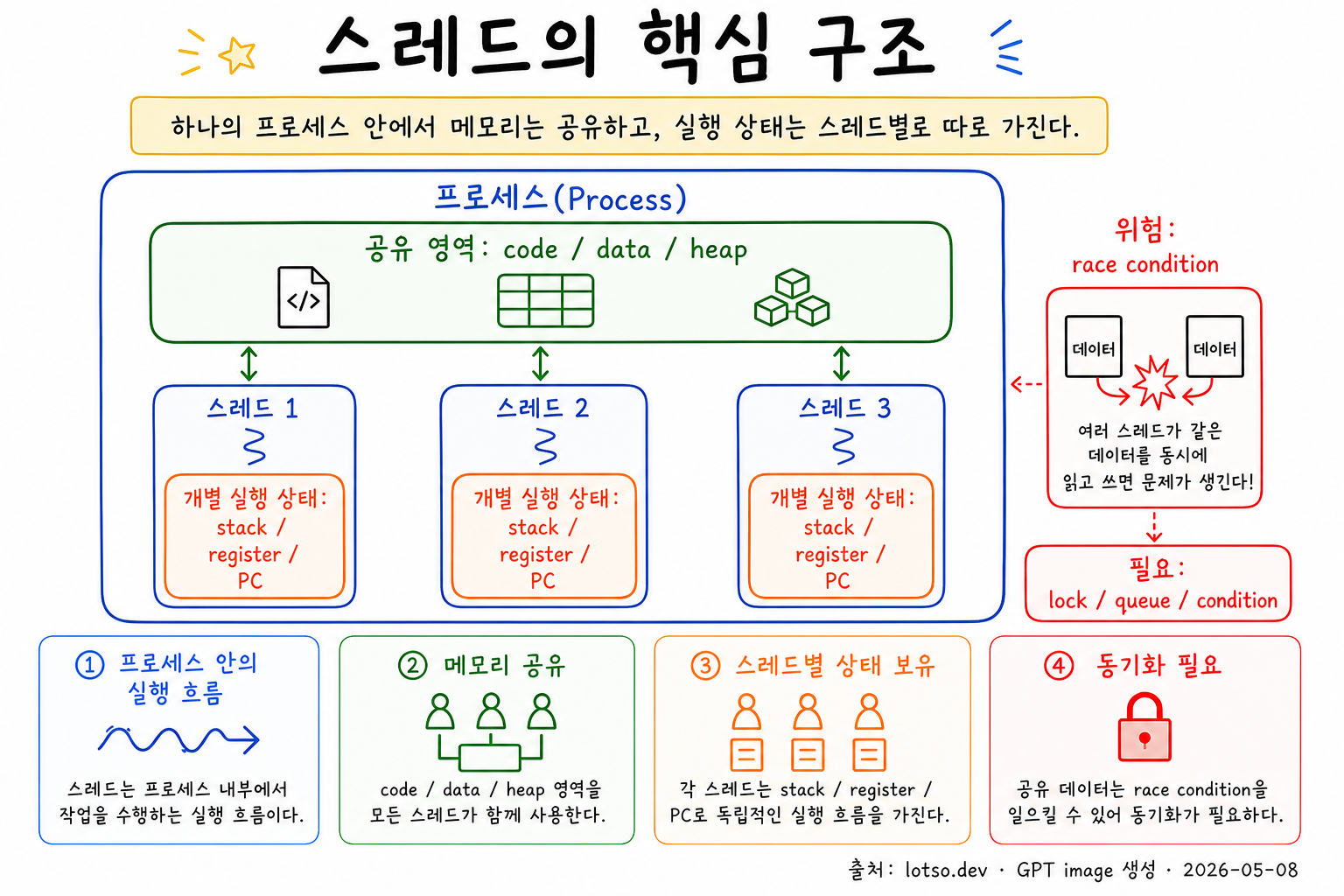
스레드는 프로세스 내부에서 실제 작업을 수행하는 실행 흐름이다. 하나의 프로세스는 하나 이상의 스레드를 가질 수 있다. 이 노트는 기본적으로 POSIX/Linux의 운영체제 수준 스레드를 기준으로 설명한다.
운영체제 수준 스레드는 커널 스케줄러가 CPU에 올려 실행하는 단위다. 같은 프로세스 안의 다른 스레드와 code, data, heap 영역을 공유한다. 반면 각 스레드는 자신의 실행 흐름을 유지하기 위해 별도의 stack, 레지스터 상태, [[프로그램 카운터]] (PC)를 가진다.
이 구조 때문에 스레드는 명시적인 [[IPC]] 없이 같은 주소 공간을 통해 협력할 수 있다. 하지만 [[공유 메모리]]는 동시에 위험 요소이기도 하다. 여러 스레드가 같은 데이터를 동시에 읽고 쓰면 [[race condition]]이 생길 수 있고, 이를 막으려면 [[lock]], thread-safe [[queue]], [[condition variable]] 같은 동기화 장치가 필요하다.
스레드의 핵심 성질은 공유다. 공유 덕분에 가볍고 빠르게 협력할 수 있지만, 그만큼 데이터 일관성과 동기화 책임을 고려해야 한다.
References
- The Open Group:
pthread_create— POSIX thread가 프로세스 안에서 생성되어start_routine을 실행한다는 기준. - Linux man-pages:
pthreads(7)— 한 프로세스의 여러 스레드가data/heap을 공유하고 각자stack을 가진다는 Linux/POSIX 설명.
Connections
- 프로세스 — 스레드가 속해 있는 실행 자원과 주소 공간의 경계
- [[프로세스와 스레드의 차이]] — 스레드의 공유 특성과 프로세스의 격리 특성을 비교하는 관계 노트
- [[공유 메모리]] — 스레드가 빠르게 협력할 수 있는 이유이자 동기화 문제가 생기는 배경
- [[race condition]] — 공유 상태를 동시에 다룰 때 생기는 대표적인 오류
- [[lock]] — race condition을 막기 위한 기본 동기화 장치
- [[컨텍스트 스위칭]] — CPU가 실행 흐름을 바꾸는 비용
- [[멀티스레딩]] — 하나의 프로세스 안에서 여러 스레드로 작업을 처리하는 실행 방식
- [[Python 스레드는 CPU 병렬성보다 I/O 동시성에 적합하다]] — CPython과 GIL 맥락에서 스레드의 사용처를 정리할 후속 노트
Discussion
Comments
댓글은 승인 후 공개됩니다.